Archivio per la categoria ‘Dati’
7 giugno, 2013 | di Giovanni Allegri
 L’11 Febbraio 2013 sarà una data passata inosservata ai più, ma per chiunque operi nel campo della geomatica segna una tappa importante per l’osservazione dallo spazio: il programma Landsat entra in una nuova fase della sua storia con il Landsat Data Continuity Mission (LCDM) . Sulla spinta di un vettore Atlas-V, un nuovo satellite per l’osservazione terrestre è stato lanciato dalla base americana di Vandenberg, diretto nella sua orbita eliosincrona, a 705 km dalla Terra, pronto ad inondarci e ad affascinarci con nuove immagini del nostro pianeta.
L’11 Febbraio 2013 sarà una data passata inosservata ai più, ma per chiunque operi nel campo della geomatica segna una tappa importante per l’osservazione dallo spazio: il programma Landsat entra in una nuova fase della sua storia con il Landsat Data Continuity Mission (LCDM) . Sulla spinta di un vettore Atlas-V, un nuovo satellite per l’osservazione terrestre è stato lanciato dalla base americana di Vandenberg, diretto nella sua orbita eliosincrona, a 705 km dalla Terra, pronto ad inondarci e ad affascinarci con nuove immagini del nostro pianeta.

Le immagini ottenute dai Landsat sono, probabilmente, le più note ed utilizzate a livello mondiale. Oltre agli impieghi scientifici e militari, sono derivate dal Landsat 7 anche le immagini impiegate nei più noti servizi di web mapping. L’esempio più noto e popolare è senz’altro Google, che nei prodotti Maps e Earth impiega la rielaborazione TrueEarth, realizzata da Terrametrics. Altri grandi nomi sono MSN, Yahoo, il progetto NASA World-Wind e, più recentemente MapBox che ha realizzato autonomamente una copertura d’immagini mondiale, che prossimamente potrà essere impiegata come base nelle mappe realizzate tramite i loro servizi cloud.
Dal 30 Maggio l’LCDM, gestito da NASA e USGS, ha iniziato ad acquisire le prime immagini ed è stato rinominato in Landsat 8, proseguendo la numerazione iniziata nel 1972 con il lancio del Landsat 1, dotato di sensore MSS (Multispectral Scanner System) che acquisiva dati nelle bande del rosso e del verde e due nell’infrarosso, con una risoluzione spaziale di 68m x 83m. Ne hanno fatta di strada i sensori da allora!
I due “occhi”, a bordo del Landsat 8, sono composti dai nuovi sensori OLI (Operational Land Imager) e TIRS (Thermal Infrared Sensor), che garantiranno prestazioni e qualità di ripresa superiori al precedente ETM+, grazie anche ad un numero maggiore di bande, 11 contro le precedenti 8. In particolare sono state aggiunte due bande ottimizzate per lo studio dei cirri (1360/1380 nm) e dell’aerosol (430-450 nm) e il range nell’infrarosso termico è stato suddiviso in due bande, contro l’unica grande banda dell’ETM+
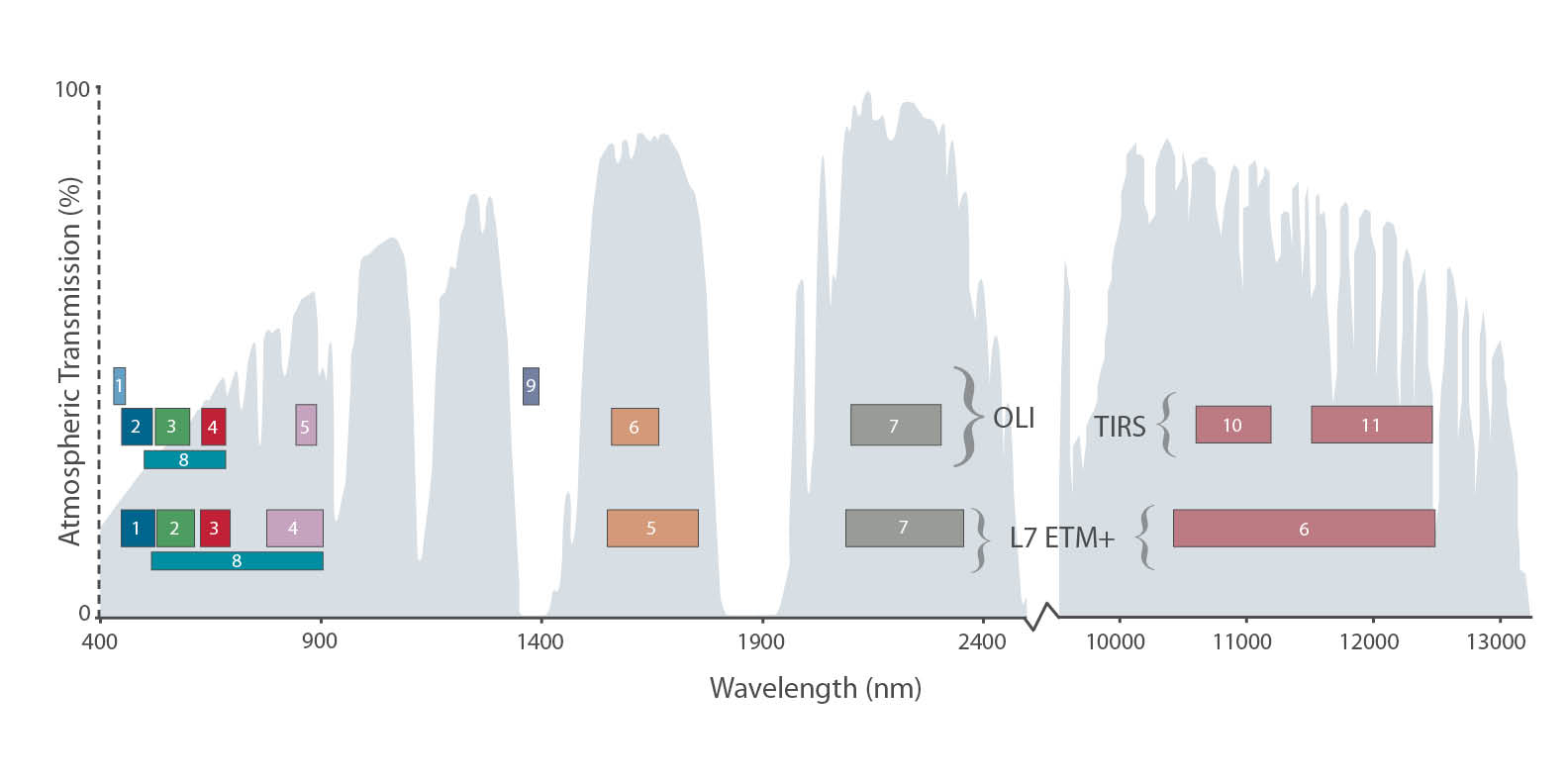
Confronto tra le bande dei sensori ETM+ e OLI+TIRS (fonte USGS)
Come si può vedere nell’immagine, è stato inoltre ampliato il range spettrale del canale pancromatico (banda 8), che come il suo predecessore continuerà ad acquisire con una risoluzione spaziale di 15m. Per le immagini nel visibile si tratta di una risoluzione sufficiente per le scale medie; se non vi basta preparatevi a sborsare come minimo 500$ per 25 Kmq d’immagini d’archivio QuickBird a 60cm, o un po’ di più per i GeoEye-1/2 (di proprietà NASA e Google)
Le immagini elaborate dai dati Landsat saranno distribuite in formato Geotiff a 16 bit, georiferite rispetto al sistema di riferimento WGS84, con proiezione UTM, ortorettificate e corrette tramite un processamento Level 1T – Terrain Correction (ovvero sono già corrette radiometricamente e geometricamente, ed inoltre sono corretti/minimizzati gli errori di parallasse dovuti al rilievo del terreno). Per il sensore OLI viene garantita un’accuratezza CE90 di 12 metri (la reale posizione geografica di un elemento si trova, al 90% di probabilità, entro un un cerchio di 12 metri di diametro rispetto alla sua posizione nell’immagine), e di 41 m per il TIRS.
Ogni 8 giorni il Landsat 8 ci offrirà una copertura completa della Terra, e le immagini ottenute dal sensore OLI potranno essere visualizzate e scaricate liberamente tramite il LandsatLook Viewer dell’USGS. Sarà possibile scaricare sia l’immagine visualizzata nel viewer, come JPEG, PNG o TIFF georiferita, oppure eseguire un “bulk download”, ovvero scaricare i dati originali della scena richiesta, più l’immagine in colori naturali e nel termico. Ciò significa, mediamente, 1 GB di dati.
Nel seguente breve videotutorial vi mostro quanto sia semplice ottenere i dati Landsat e delle immagine pronte per essere usate in un qualsiasi ambiente GIS. Nell’esempio sovrapporrò un’immagine dell’Etna, del 4 Giugno, su una base OpenStreetMap all’interno di QuantumGIS.

Buona esplorazione.
Giovanni Allegri
Posted in Dati | 3 Comments »
7 maggio, 2013 | di Andrea Borruso
Introduzione
NDR: questo articolo viene pubblicato in contemporanea anche su MobilitaPalermo, un importante blog cittadino non “tecnico”. Per questa ragione nel testo sono stati inseriti dei riferimenti che potranno sembrare scontati per il lettore “tipico” di TANTO.
Il 23 febbraio di quest’anno, in occasione del primo Open Data Day italiano, ho assistito alla presentazione della strategia Open Data del Comune di Palermo.
Sono andato con entusiasmo all’incontro, ma sono tornato a casa pieno di dubbi, perché in quell’occasione ho avuto la sensazione che di strategia ce ne fosse poca, e che il Comune stesse realizzando l’apertura dei dati detenuti con poca consapevolezza.
Non è stato presentato un documento sulle linee guida, né tantomeno è stata annunciata una sua imminente realizzazione. Non è stata data alcuna comunicazione sugli investimenti ed il budget messo a disposizione per il mantenimento e l’ulteriore sviluppo del piano inerente la liberalizzazione dei dati. Sono state accennate, peraltro in modo molto generale, un paio di evoluzioni possibili del progetto, ma senza associarle ad una scadenza temporale, e non definendone le modalità di realizzazione.
Si è ancora in tempo per fare, ad esempio, queste due attività di divulgazione:
- esplicitare ai cittadini l’intero iter che si vuole seguire, definendo con chiarezza: cosa ci si aspetta di ottenere; quali impegni concreti prende l’amministrazione; a quali vincoli le decisioni sono sottoposte (normativi, finanziari, istituzionali, ecc.);
- fornire tutte le informazioni necessarie affinché la partecipazione dei cittadini si possa basare su una conoscenza approfondita dei temi oggetto di discussione e non su semplici sensazioni;
Sono due punti “rubati” da un bell’articolo di Claudio Forghieri. L’articolo parla d’altro, di crowdsourcing applicata alla Pubblica Amministrazione, ma contiene diversi spunti utili per il tema degli OpenData, sia per i decisori che per i cittadini.
Discutere di dati aperti significa parlare di trasparenza dell’attività della P.A., ma anche e soprattutto, in questo momento di crisi, di opportunità per i cittadini, per gli sviluppatori, per le aziende.
Come detto, dalle istituzioni ci si aspetta, quanto meno, che venga tracciata una road map da seguire (si confronti, ad esempio, i principi chiave sugli open data del Comune di Milano con la sezione opendata del Comune di Palermo), ma anche che le stesse istituzioni interagiscano con la società civile (cittadini, aziende, ecc.).
Le due aspettative sono state finora entrambe disattese.
A distanza di due mesi da quella presentazione, non riscontro evidenze che migliorino questo quadro e navigando sul sito saltano subito agli occhi questi elementi:
- dal giorno del lancio non sono stati pubblicati nuovi dataset. Se ne ha evidenza nel box “Ultimi dataset” presente sulla pagina web del Comune dedicata agli Open Data;
- non è stato inserito un motore di ricerca dedicato, né tantomeno i dati sono pubblicati in modo da “essere facilmente identificabili in rete, grazie a cataloghi e archivi facilmente indicizzabili dai motori di ricerca” (vademecum OpenData);
- alcuni dati sono pubblicati in formato proprietario (ad esempio il formato .rar);
- i dataset non sono strutturati in modo tale da essere presentati in maniera sufficientemente granulare, così che possano essere sempre utilizzati dagli utenti per integrarli e aggregarli con altri dati e contenuti in formato digitale (Project Work Open Government Data)
- i dataset hanno un corredo scarso di metadati descrittivi;
- soltanto due dataset sono stati fatti confluire verso dati.gov.it, il Portale nazionale dei dati aperti.
Ho scritto quattro email al Comune di Palermo e non ho mai avuto alcuna risposta. Nel giorno della presentazione era stato chiesto ai presenti di vivere in modo partecipato l’iniziativa, e che i responsabili del Comune sarebbero stati in ascolto e lieti di ricevere contributi dai cittadini. Sulla sezione del sito dedicata si legge: “Se vuoi proporre la pubblicazione di ulteriori dati interessanti e/o per eventuali segnalazioni contattaci“.
L’esperienza professionale e umana mi ha avvicinato molto al mondo degli Open Data. Per tale ragione scriverò a seguire anche alcune cose un po’ più “tecniche” e specifiche, perché l’esperienza è anche un grande supporto alla comunicazione. Partirò proprio dalle email che ho inviato.
Nella prima scrivevo “[...] solo per consigliarvi di non usare il formato .rar per i file compressi, in quanto è un formato proprietario [...].” Come detto, oltre a non ricevere alcuna risposta, i file .rar continuano ad essere presenti nel sito (ad esempio qui).
Nella seconda, in riferimento al dataset “PERIMETRAZIONE CIRCOSCRIZIONI COMUNALI“, scrivevo: “[...] è presente una grave lacuna: manca il file con la definizione del sistema di coordinate.[...]“. Il dataset è ancora sprovvisto di questa informazione fondamentale.
Nella terza segnalavo che il dataset “ELEZIONI AMMINISTRATIVE 2012 - AFFLUENZA ALLE URNE” non fosse scaricabile. Da qualche giorno è possibile farne il download.
Nell’ultima, un po’ più complessa, facevo notare come il dataset “TURISMO - ELENCO DEI SITI TURISTICI VISITABILI” contenesse alcuni errori. Questi sembrano stati corretti, ma l’ho scoperto per caso oggi.
Suggerisco al comune di creare un sistema di feedback, al limite anche automatico, altrimenti qualsiasi sistema di segnalazione non ha quasi alcuna utilità funzionale e sostanziale.
Quest’ultimo dataset è quello più scaricato, quello che sembra più interessante per gli utenti del sito. Incuriosito dal numero di download l’ho scaricato ed ho provato a farci qualcosa, con l’obiettivo di testare concretamente l’efficacia di questa azione e di restituire anche qualcosa indietro.
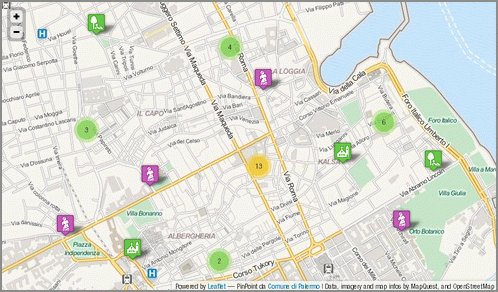
Il dataset dei siti turistici visitabili della città di Palermo
Palermo è una città con un centro storico molto grande (in alcune classifiche è riportato come il più grande d’Europa). E’ quindi di elevato interesse turistico e ricca di siti visitabili. Pubblicare in Open Data questo dataset è un’ottima scelta, perché si presta potenzialmente ad uno degli scopi principali di questo tipo di azione: il riuso da parte di cittadini, professionisti e aziende. Una persona, infatti, potrebbe scaricare questi dati e farne ad esempio una app per smartphone, utile a chiunque voglia scoprire questa bella città. Realizzarla in più lingue, metterla in vendita in uno store dedicato, guadagnare il giusto e contribuire a rendere Palermo più fruibile.
Il dataset relativo è così descritto sul sito:
La tabella contiene i dati relativi ai siti turistici visitabili in città. Sono distinti il tipo sito, la denomianzione del sito, la descrizione, l’indirizzo, info, orario di accesso al sito, note relative all’orario di accesso al sito, l’eventuale necessità di biglietto di ingresso con i relativi costi ed esenzioni, contatto mail, sito web dedicato, note per eventuali visite guidate ove possibile, informazioni sull’accessibilità.
La descrizione, a parte un piccolo errore di battitura (“denomianzione” per “denominazione”), è chiara e abbastanza autoconsistente. Del dato originale però non sappiamo altro, salvo il suo formato (.csv) e il nome del responsabile (Dott. Eliana Calandra).
Sono presenti in realtà altre informazioni – come ad esempio la “Data di creazione” – ma non riguardano il dato originale, e lo descrivono soltanto in relazione alla sua pubblicazione nella sezione Open Data del sito del Comune.
L’assenza di informazioni fondamentali sul dataset e propedeutiche affinché il dato possa essere realmente usato e abbia un valore concreto, ne sminuisce fortemente il valore e la sua usabilità, vanificando, di fatto, lo scopo per il quale è stato pubblicato.
Ad esempio, uno di questi è l’indicazione della data di aggiornamento: quando è stato redatto questo archivio?
Un dataset turistico deve essere recente ed aggiornato per avere valore, infatti cambiano con una certa frequenza elementi informativi come: costi di eventuali biglietti ingresso, orari di apertura, numeri di telefono, ecc..
Altra informazione omessa nella pubblicazione del dataset è quella relativa alla scelta progettuale che c’è alle spalle dell’archivio. Contiene 100 siti. Viene da domandarsi: sono tutti quelli visitabili in questa città? Se non lo sono, che filtro è stato applicato? Sono 100 perché si è filtrato soltanto in base a “chiese e oratori” (59), “musei e gallerie d’arte” (26) e “ville e giardini” (15)? Perché ci sono siti di Bagheria e non di altri comuni?
Il dataset analizzato si presta alla rappresentazione cartografica, ma non contiene le coordinate dei vari siti contenuti. Tuttavia è presente l’indirizzo ed è su questo che ho eseguito un’operazione di geocoding.
Prima di farlo però, l’ho analizzato un po’ più nei dettagli. A seguire alcuni degli elementi riscontrati:
- l’anno di costruzione dei siti è inserito nel campo “Nome del sito”. In questo modo è un’informazione poco utilizzabile. Sarebbe preferibile inserirla in un campo dedicato (l’ho fatto). Che questo numero presente nel campo sia l’anno di costruzione è una mia deduzione, ma non posso esserne certo.
- ci sono due righe per la “Chiesa di S. Maria in Valverde (1633)”. L’unica differenza sembra l’indirizzo, ma tutti gli altri dati sembrano coincidenti.
- ci sono 8 strutture in cui non è inserito il numero di telefono. Per un dataset di questo tipo è una grave lacuna; basti pensare che mancano quelli dell’Orto Botanico e della Cappella Palatina.
- il campo “info” contiene essenzialmente i numeri di telefono, ma mescolati alle volte con elementi altrettanto utili come “Sito è visitabile solo in occasione di mostre e/o eventi” o “Chiusa per restauro”. Penso che sarebbe preferibile creare un campo “telefono”, distinto da un generico “info”.
- il campo “indirizzo email”, importantissimo a fini turistici, non è mai valorizzato. In realtà lo è una sola volta, nel caso della “Chiesa di S. Cristina La Vetere (1174)”, ma è stato scambiato con il valore contenuto nel campo “sito web” (l’ho modificato).
- gli URL dei siti web sono inseriti di solito con questa struttura ” www.nomesito.it“. Alcuni record però sono difformi (“http://www.nomesito.it” o ad esempio “web: www.nomesito.it”). Li ho uniformati alla struttura www.nomesito.it
- nel campo “descrizione del sito” è possibile leggere sia “chiesa” che “Chiesa”, “Cappella” e “cappella”; ho uniformato i nomi di categoria in minuscolo.
- solo la “Cattedrale” ha informazioni sull’accessibilità. Mi sembra un’informazione propedeutica per qualsiasi dataset di informazioni su siti turistici.
- sono presenti numerosi spazi doppi, ed alcuni caratteri di tabulazione, che non hanno ragione di essere presenti, e che disturbano la gran parte delle eleborazioni automatiche via software.
- il nome via corretto per “Corso Vittorio Emanuele” dovrebbe essere “Via Vittorio Emanuele”.
Fatta questa rapida analisi del dato, sono passato a fare il geocoding sfruttando le API dedicate di Google. Queste consentono con una chiamata in HTTP, partendo da un indirizzo postale, di avere restituito (tra le altre cose) latitudine e longitudine dell’indirizzo. Per conoscere, ad esempio, quelle di “Via Terrasanta 82, Palermo” lancerò questo URL:
http://maps.googleapis.com/maps/api/geocode/xml?
address=Via%20Terrasanta%2082,%20Palermo&sensor=false
L’output in questo caso è in XML e tra le informazioni che mi vengono restituite ci sono proprio quelle che cerco, latitudine e longitudine:
<location>
<lat>38.1303072</lat>
<lng>13.3445130</lng>
</location>
Ma si tratta soltanto di uno strumento e come tale ha anche lui i suoi problemi. Due esempi tra tanti:
- non sono presenti nel database di Google tutti i numeri civici, come ad esempio “Piazza Casa Professa, 21″ o “Piazza S. Valverde, 3″. Il problema è risolvibile integrando gli strumenti di Google a quelli di Bing Maps, Pagine Gialle, OpenStreetMap, e lo sarà ancora di più quando il comune pubblicherà in Open Data il dataset del viario e dei numeri civici.
- in Google Maps si legge “Via Nasi Nunzio, 18, Palermo” e non “Via Nunzio Nasi, 18, Palermo”, e si inverte il classico ordine “Nome Cognome”
Il problema principale legato alla geocodifica è che però la metà dei siti sono associati ad indirizzi senza numero civico, e quindi non è possibile ricavarne la posizione automaticamente. Questa è una lacuna che non è del dato in quanto tale, ma un vero e proprio “vuoto toponomastico”: non esiste un numero civico per ogni ingresso ad un edificio di una città.
Il lavoro che ho fatto è quindi incompleto, perché per questa demo mi sono fermato a ciò che era possibile automatizzare.
L’analisi e la pulizia dei dati, così come il geocoding sugli indirizzi, li ho fatti con un bellissimo software open-source multipiattaforma, che nasce proprio per ripulire i dati e derivare nuove informazioni:OpenRefine (spero di scriverci un tutorial quanto prima).
Ricavate le coordinate dei siti, ho pensato subito di pubblicare i dati online, realizzando una piccola applicazione di webmapping a solo scopo dimostrativo, che mostrasse quanto fosse semplice realizzare un prodotto gradevole, utile, moderno, i cui costi fossero soltanto legati al tempo di sviluppo.
Ho utilizzato infatti soltanto software open-source. L’ho fatto per ragioni di personale comodità, in quanto sono quelli che utilizzo maggiormente, ma anche per la grande qualità e per le funzioni disponibili.
Da OpenRefine ho estratto un file .csv, che ho convertito in GeoJSON con l’utility ogr2ogr messa a disposizione dalla libreria GDAL. Il GeoJSON è un formato ormai “classico” nel mondo del web-mapping e nativamente supportato da Leaflet, la meravigliosa libreria usata per fare questa piccola applicazione di cartografia online.
E’ molto bella perché ben documentata, di semplice utilizzo, ricca di feature e (come dicevo anche prima) moderna. Due prove evidenti sono la leggibilità della mappa prodotta su dispositivi mobili, e la possibilità (tramite plugin) di aggregare in cluster indicatori di posizione molto vicini. Nella mappa infatti tutte le volte che ad un certo livello di zoom gli indicatori sono troppo vicini, e quindi poco leggibili, vengono raggruppati in un simbolo circolare, con sovrimpresso un numero che indica da quanti elementi è formato; al click sul simbolo, si avvierà automaticamente lo zoom sulla mappa, e verranno mostrati tutti gli elementi che compongono il gruppo.
Prima di scegliere questo dataset e questo output, ho navigato un po’ nella sezione OpenData del sito del Comune, ho trovato limitante l’assenza sul sito di un motore di ricerca dedicato che mi consentisse, ad esempio, di filtrare soltanto i dati pubblicati in formato .shp (un classico formato cartografico). Ne ho costruito uno con Google Custom Search Engine (che il Comune usa per l’intero sito), con il quale posso risalire rapidamente ai soli dataset pubblicati in questo formato (basta inserire “shape” come parola chiave) o ai cinque in .csv (usate “csv” in questo caso).
Infine ho pubblicato tutto in un minisito dedicato, realizzato con Twitter Bootstrap, dove troverete:
In conclusione
Mi rendo perfettamente conto che è facile fare critiche.
Ed è per questo che ho voluto concretamente indicare cosa ci si aspetta dalle Istituzioni quando queste dicono di “fare Open Data”. Per la stessa ragione ho voluto mettere in piedi un esempio di applicazione costruita a partire dai dati pubblicati dal Comune, una piccola cosa concreta.
L’operazione di trasparenza, innanzitutto, prende le sue mosse da una progettualità, che anch’essa deve essere correttamente descritta ed esplicitata: quali sono le finalità, quali sono le linee guida, quali sono le modalità operative, qual è il budget a disposizione, quali sono le evoluzioni e gli incrementi previsti, quali sono le modalità comunicative.
In secondo luogo, è necessario avere cura di rendere disponibili dati di qualità.
Il valore del dato aperto risiede nell’accuratezza dello stesso e nella sua ri-usabilità.
Non è solo un problema di trasparenza della P.A..
Non è solo una questione etica per cui è giusto che il lavoro della P.A. e le informazioni dalla stessa raccolte e detenute vengano poi restituite ai cittadini ed agli utenti che sono i contribuenti.
Non si tratta soltanto di correttezza metodologica e/o scientifica per cui ci si aspetta che l’elaborazione del dato avvenga secondo determinati criteri e standard elevati.
Dati di qualità, e solo questi, consentono di assolvere alla funzione per cui essi sono raccolti e pubblicati: è un problema economico, nel senso di utilizzo delle risorse per soddisfare al meglio bisogni individuali e collettivi.
Un dato aggiornato ed accurato consente il suo utilizzo nei modi più svariati.
David Miller, Sindaco di Toronto, ebbe a dire: “una volta liberati i dati, non c’è limite a quello che le persone possono farci“.
Per questo ritengo che pubblicare un tweet come questo ” Trasparenza e innovazione. Palermo VII in Italia.”
oltre che non corretto (perché si riferisce solo alla quantità di dati) non ha senso. Quantità senza qualità non serve a nulla.
Nello stesso tweet leggo con piacere di una App ufficiale. Peccato non averla agganciata ad una gara tra sviluppatori/progettisti, per la migliore applicazione costruita a partire da dati pubblicati (anche) in Open Data.
Qualche giorno addietro ho condiviso su twitter un articolo: Open Data in Agriculture and Why It Matters. Una frase di questo articolo, che parla del valore degli Open Data nell’agricoltura, mi ha colpito: “ottimizzare il processo decisionale“.
Se l’Amministrazione apre e diffonde la propria conoscenza (i dati dalla stessa detenuti) otterrà un sicuro ritorno in termini di produttività e di partecipazione della cittadinanza, in termini di ricerca e di innovazione. Tutti elementi, questi che sospingono, specialmente in questi momenti di crisi, la crescita economica e sociale di una collettività.
Gli open data sono una opportunità per il Paese. Si tratta di crederci (la P.A. ci deve credere). Leggere in un recentissimo comunicato stampa che “Il nuovo Statuto del Comune si ispirerà ai principi della trasparenza e della partecipazione e su riconoscimento, tutela e valorizzazione dei beni comuni“, mi deve fare pensare che questa amministrazione ci vuole credere. Ma questo lo diranno i fatti.
Così come devo supporre e voglio sperare che i dataset a disposizione del Comune non abbiano le stesse caratteristiche di quello descritto in questo post. Viceversa gli amministratori di questa città non avrebbero gli strumenti adeguati per gestirla bene.
Alla presentazione della strategia Open Data del Comune di Palermo è stato chiesto alla cittadinanza di contribuire all’apertura dei dati. Giusto!
A due mesi della detta presentazione vorrei, provocatoriamente, parafrasare (ribaltandola) la famosa frase di J.F.Kennedy: “non chiedetevi cosa possono fare i cittadini per l’apertura dei dati, chiedetevi cosa deve fare l’Amministrazione per produrre dati di qualità.“
Posted in Dati | 12 Comments »
19 marzo, 2013 | di Andrea Borruso
 Il 23 febbraio sono stato a Roma alla prima conferenza organizzata dall’associazione OpenGeoData Italia. Ne sono stato – per conto di TANTO - uno dei relatori e sono contento di aver partecipato. Le ragioni sono diverse e ne voglio elencare solo alcune:
Il 23 febbraio sono stato a Roma alla prima conferenza organizzata dall’associazione OpenGeoData Italia. Ne sono stato – per conto di TANTO - uno dei relatori e sono contento di aver partecipato. Le ragioni sono diverse e ne voglio elencare solo alcune:
- ho avuto la possibilità di avere un quadro di quello che avviene sul tema in Italia;
- ho incontrato persone che troppo spesso incrocio soltanto virtualmente (napo, Massimo Zotti, GimmiGIS, Antonio Rotundo, Giovanni Biallo, …) ;
- ho stretto la mano a Ernesto Belisario, Martin Koppenhoefer e Gianluca Vannuccini;
- ho preso una pausa contro il “logorio della vita moderna”, fatta anche di chiacchiere e birra con il presidente.
Cosa voglio di più? In realtà avrei proprio voluto incontrare un lucano, ma questa è un’altra storia ed è un po’ “up, close and personal”.
La nostra relazione aveva come obiettivo quello di proporre (ed in un certo senso anche quello di verificarne l’esigenza) un’azione per la crescita della consapevolezza del valore degli OpenGeoData, che contribuisca a fare in modo che non rimangano soltanto un obbligo di legge, una moda e uno sfogo per (geo)geek. Non conoscevo i contenuti delle presentazioni degli altri relatori, ma ascoltandoli ho compreso chiaramente che si trattava di un’esigenza condivisa da molti e sono tornato a Palermo “forte” di diversi riscontri.
Ieri pomeriggio però mi ha preso un po’ lo sconforto. Volevo raccogliere degli elementi, per costruire un elenco commentato di casi tipo di “pregio”, da usare come strumento divulgativo classico. Ho consultato alcuni siti web di importanti comuni del Nord e del Sud Italia, concentrandomi sulla sezione geografica dei dataset disponibili e due elementi mi sono saltati agli occhi.
Il primo è un errore, anzi come diceva la mia professoressa di Matematica “un orrore”, ma per fortuna molto poco diffuso: layer cartografici in formato .shp non accompagnati da file .prj. Non può bastare – come avviene – scrivere nella pagina di descrizione dello specifico dataset “Sistema di riferimento UTM ED50”. Fatto il download del dato (che contiene i soli .shp, .shx e .dbf) il virus ha iniziato già a diffondersi: io infatti magari passerò il file .zip ad un mio collega senza precisargli il sistema di coordinate letto nella pagina, ed in due passaggi ho compromesso in modo grave la qualità del dato.
Il secondo purtroppo è qualcosa di molto diffuso e ha radici che non riguardano gli OpenGeoData, ma che in questo contesto fanno tanto “male”. Ho aperto diversi dataset spaziali scaricabili in formato .shp, ne ho fatto il download e ho visualizzato in un client le tabelle associate. Mi sono trovato davanti nomi di campo di questo tipo: “AFFIDARE_A”, “TIPO_MANU1”, “ARRE_GESTI” e anche il meraviglioso “GIANCARLO”. Il formato .dbf – con tutti i suoi limiti – ci mette il suo, ma pubblicare un dato, senza accompagnarlo con un file che ne descriva nel dettaglio il contenuto informativo, mi pare un “non senso” e mi fa pensare ad un paio di indimenticabili caffè bevuti in case in cui i barattoli di sale e zucchero non avevano etichette.
Il primo elemento è per fortuna poco diffuso e di soluzione banale, perché esistendo già uno standard per descrivere il sistema di coordinate di un file .shp, si possono implementare delle semplici procedure di controllo.
Il secondo è molto più complicato perché da anni tutti noi produciamo file .shp, ma senza porci il problema di descriverne il contenuto informativo e stavolta in un solo passaggio impoveriamo il valore del nostro dataset.
Andare verso le 5 stelle dei Linked Open Data e verso INSPIRE in qualche modo risolverebbe problemi di questo tipo, ma ad oggi la gran parte degli OpenGeoData vengono pubblicati principalmente in modalità più “semplici” e penso sia necessario trovare una “cura” prima possibile.
Che ne pensate?
Il tema è vasto e l’intento di queste
post è soltanto costruttivo e vale soltanto come apripista dell’iniziativa che vogliamo lanciare in modo corale.
Oggi fra l’altro è un giorno speciale, perché scatta l’open by default: ”dati e documenti pubblicati online dalle amministrazioni titolari – senza una esplicita licenza d’uso che ne definisca le possibilità e i limiti di riutilizzo – sono da intendersi come dati aperti, quindi dati che possono essere liberamente acquisiti da chiunque e riutilizzabili anche per fini commerciali.”
Foto di jlib
Posted in Dati | 26 Comments »
8 febbraio, 2013 | di Antonio Falciano
Una novità che sta circolando da poco più di un mese a questa parte e che, in pratica, interessa tutta la comunità italiana di fruitori dell’informazione geografica, consiste nella recentissima attivazione del servizio di trasformazione di coordinate ad opera del Geoportale Nazionale (ex Portale Cartografico Nazionale). Tale tipologia di servizio rientra tra gli adempimenti previsti dalle Implementing Rules della Direttiva europea INSPIRE (2007/2/EC), al fine di assicurare la condivisione e l’interoperabilità di dataset e servizi, adottando formati e specifiche comuni, tra tutti i nodi dell’infrastruttura di dati spaziali europea. In particolare, l’implementazione di tale servizio da parte del GN consiste in:
Per ulteriori approfondimenti circa le premesse e i dettagli tecnici, si consiglia la lettura di questo articolo sulla rivista Geomedia.
Benissimo! “Lasciamoci INSPIR(ar)E” dunque, parafrasando il titolo di un gran bel post di Pietro Blu Giandonato di qualche anno fa… E cosa avviene a livello regionale? In verità, esiste già qualche servizio analogo, tra cui:
Per curiosità, dopo aver letto un post nella lista GFOSS in cui erano segnalate delle inaspettate anomalie, ho deciso di impiegare qualche ritaglio di tempo libero per verificare la bontà del servizio WCTS della mia regione, la Basilicata, rispetto a quello appena reso disponibile dal GN. Nel seguito, non mi addentrerò nella descrizione qualitativa dei servizi (della serie …è più bello, è più brutto, è più veloce, mi chiede l’indirizzo email, ecc.), poiché esula completamente dai miei scopi.
In pratica, ho effettuato le seguenti operazioni:
- ho scaricato i confini amministrativi regionali dal sito dell’ISTAT, definiti in EPSG:23032, e li ho caricati in una vista di gvSIG 1.12, definita nello stesso sistema;
- ho poi selezionato solo la mia regione e applicato l’algoritmo di SEXTANTE “Adjust n points to polygon”, in modo tale da generare un set di 100 punti scelti in maniera casuale contenuti in Basilicata, utilizzando i parametri rappresentati in Figura 1 e ottenendo il risultato in Figura 2;
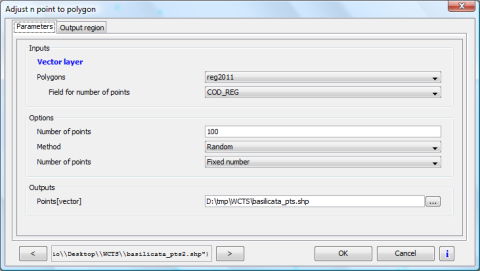
Figura 1 – Adjust n points to polygon
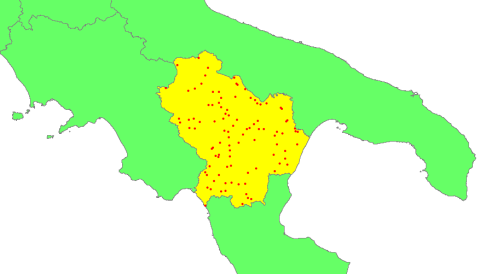
Figura 2 – Layer di punti casuali
- ho quindi trasformato il layer di punti precedentemente ottenuto, utilizzando sia l’applicazione web del Geoportale Nazionale che quella della Regione Basilicata, rispettivamente dal sistema EPSG:23032 (ereditato dal layer dei confini amministrativi ISTAT) verso EPSG:3004 e EPSG:32633, assumendo per buona ad occhi chiusi la conversione dovuta al passaggio di fuso/zona contenuta in maniera implicita in entrambe le trasformazioni, in quanto si tratta di un’operazione di coordinate che i software e le librerie GIS generalmente affrontano in maniera rigorosa e quindi fuori di discussione. Inoltre, ho trasformato – sempre utilizzando entrambi i servizi – il layer dei punti definito in EPSG:32633 ottenuto dal GN verso EPSG:3004. In definitiva, ho ottenuto tre coppie di layer, ognuna corrispondente ad ogni trasformazione possibile tra i tre sistemi citati e definita in un preciso sistema di destinazione. In Figura 3 sono rappresentate schematicamente le singole trasformazioni realizzate.
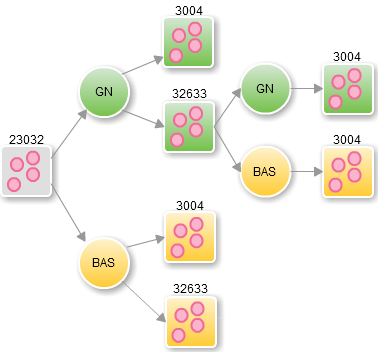
Figura 3 – Trasformazioni realizzate (Autore: Andrea Borruso)
- Il passo successivo è stato quello di definire e calcolare dei nuovi campi nelle tabelle associate ai layer ottenuti al punto precedente, contenenti le coordinate nei rispettivi sistemi di appartenenza (esistono diversi modi di farlo in gvSIG: con il “Calcolatore di campo”, con lo strumento “Aggiungi informazioni geometriche”, con “Add coordinates to points” di SEXTANTE …e tanti altri). Ho rinominato tali campi di coordinate in modo da poterli rapidamente associare al CRS di appartenenza, oltre che allo specifico servizio utilizzato. Ad esempio, X3004GN rappresenta la coordinata Est nel sistema EPSG:3004 trasformata dal Geoportale Nazionale, mentre X3004BAS è la corrispondente coordinata trasformata tramite il geoportale lucano.
- A questo punto, essendomi dimenticato di definire un campo identificativo da utilizzare come chiave esterna (in questo caso poco male, essendo i punti reciprocamente abbastanza distanti tra loro), ho eseguito il geoprocesso “Spatial join” per ogni coppia di layer definiti nello stesso CRS, selezionando l’opzione “Usa la geometria più prossima”, in alternativa al classico join tra tabelle. Il risultato di tale operazione è praticamente equivalente a quello del join, ad eccezione del fatto che gvSIG restituisce un campo DIST delle distanze tra le geometrie poste in relazione e, inoltre, il layer ottenuto è salvato su disco.
- Dulcis in fundo, ho calcolato le differenze tra coordinate omologhe al fine di verificare la bontà della trasformazione dei due servizi, assumendo quelle del GN come capisaldi in quanto dovrebbero essere quelle “ufficiali”.
I risultati di tutto l’ambaradan appena descritto, sperando di non avervi fin qui annoiato, sono riportati nella tabella seguente:
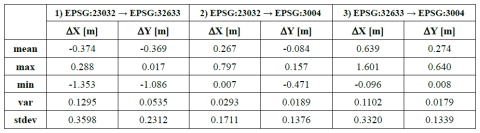
Tabella 1 – Statistiche degli scostamenti delle trasformazioni di coordinate del Geoportale della Basilicata (RSDI) rispetto a quelle del Geoportale Nazionale (GN)
A quanto pare, gli scostamenti tra le trasformazioni operate dai due servizi sono piuttosto importanti e, talvolta, addirittura superano il metro e mezzo! Se fossi un topografo, nel dubbio, mi guarderei bene dall’usare uno o l’altro servizio per trasformare i dati di un rilievo ad alta precisione. Ma anche un operatore GIS potrebbe imbattersi in qualche strana incongruenza topologica accostando dati provenienti da fonti (e quindi trasformazioni) diverse. Personalmente mi sarei aspettato differenze al più dell’ordine di un paio di decimetri per coordinata, ipotizzando dietro l’applicazione web del GN l’utilizzo di un unico grigliato comprendente tutta l’Italia a maglia più larga rispetto a quella dei singoli grigliati IGM, piuttosto che un numero elevato di griglie a passo fitto, decisamente più oneroso da gestire lato server.
Dalle statistiche di Tabella 1 chiaramente non si evince quale dei due servizi sia il meno accurato rispetto ai grigliati IGM. Eppure entrambi i servizi dichiarano di utilizzarli! Sarebbe utile, a mio avviso, ripetere lo stesso test con altri servizi WCTS regionali, magari utilizzando i grigliati come termine di confronto.
E’ lecito quindi chiedersi come mai la gestione informatica dei grigliati IGM all’interno di differenti applicazioni web porta a risultati diversi. E’ chiaro che occorrerebbe disporre di un riferimento ufficiale, unico ed inequivocabile.
A tal fine, per fugare ogni dubbio, sarebbe auspicabile il rilascio di un grigliato NTv2, formato ormai gestibile da molti desktop GIS, per ognuna delle possibili trasformazioni che interessano il nostro territorio nazionale. Non parlo necessariamente di quelli che utilizzano i topografi, ma anche solo una versione opportunamente semplificata che consenta di riunificare l’Italia intera, senza perdere eccessivamente in accuratezza. L’esempio lungimirante offerto da Francia, Spagna, Portogallo, Svizzera e Germania dovrà pur significare qualcosa nell’epoca di INSPIRE!
Aggiornamento del 09/02/2013
A seguito dell’aggiornamento ufficioso del servizio di trasformazione di coordinate del GN di cui si è avuta notizia ieri, i contenuti di questo post sono già obsoleti (forse, si tratta di un record per questo blog… ma siam contenti così! )
Ho quindi ricalcolato le medie degli scostamenti tra le trasformazioni dei due geoportali utilizzando lo stesso set di punti casuali. Il risultato è che le medie degli scostamenti sono stavolta sempre inferiori ai 3 cm. Restano tuttavia degli scostamenti max e min ancora consistenti (fino a 85 cm) per la coordinata Est. I valori estremi della coordinata Nord si aggirano invece attorno ai 20 cm, fatta eccezione per la trasformazione da EPSG:23032 a EPSG:32633, dove si superano i 30 cm.
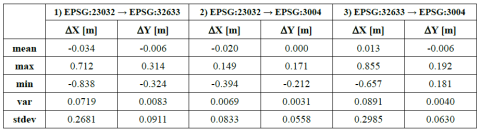
Tabella 2 – Statistiche degli scostamenti delle trasformazioni di coordinate del Geoportale della Basilicata (RSDI) rispetto a quelle del Geoportale Nazionale (GN) – agg. 09/02/2013
Resta, a mio modesto avviso, la necessità di dover rendere congruenti e quindi interoperabili i vari servizi di trasformazione di coordinate regionali con quello nazionale, evitando così l’eventuale disorientamento degli utenti. Inoltre, eviterei l’ulteriore proliferazione di servizi WCTS regionali, a questo punto ridondanti, e favorirei il rilascio e la diffusione dei grigliati NTv2, standard de facto a livello internazionale, almeno relativamente alla componente planimetrica.
Posted in Dati, osgeo | 16 Comments »
12 luglio, 2012 | di Pietro Blu Giandonato
 Finalmente il DdL “Norme sul software libero, accessibilità di dati e documenti ed hardware documentato” è stato approvato per essere convertito in legge nella seduta del Consiglio della Regione Puglia di ieri. A questo link è possibile accedere all’iter di approvazione e i relativi documenti, tra i quali il testo dell’articolato privo degli emendamenti approvati in Consiglio Regionale.
Finalmente il DdL “Norme sul software libero, accessibilità di dati e documenti ed hardware documentato” è stato approvato per essere convertito in legge nella seduta del Consiglio della Regione Puglia di ieri. A questo link è possibile accedere all’iter di approvazione e i relativi documenti, tra i quali il testo dell’articolato privo degli emendamenti approvati in Consiglio Regionale.
E’ un provvedimento che seguiamo da tempo, del quale esattamente un anno fa avevamo già fatto una analisi tesa a metterne in evidenza i punti di forza, e qualche debolezza, e per il quale ci eravamo auspicati miglioramenti soprattutto per il riuso aperto e libero dei dati pubblici. Del resto in un altro precedente articolo a commento di uno degli altri due DdL su software e dati aperti, avevamo addirittura proposto degli emendamenti, che definivano con maggiore precisione proprio il concetto di open data e relativo riuso, auspicando l’adozione di linked open data, dato che parlavamo di rintracciabilità dei dati da parte dei motori di ricerca su internet e lo scaricamento dai siti web istituzionali delle Pubbliche Amministrazioni.
In tal senso possiamo comunque ritenerci soddisfatti, poiché nel testo approvato definitivamente in Consiglio ieri è stato inserito l’articolo 6 “Riutilizzo dei documenti e dei dati pubblici”, nel quale si fa riferimento al D.Lgs. 36/2006 di recepimento della Direttiva 2003/98/CE relativa al riutilizzo di documenti nel settore pubblico (c.d. Direttiva PSI). In fondo all’articolo trovate alcuni utili riferimenti per approfondire il tema.
L’impianto del DdL nella versione della quale avevamo parlato un anno fa è stato arricchito e potenziato dal nuovo articolo 17, che istituisce una “Comunità di pratica”, aperta alle Università e al partenariato economico e sociale, e che si pone obiettivi estremamente ambiziosi:
- promuovere lo scambio, la diffusione e il riuso di esperienze, progetti e soluzioni relativi al software libero nella PA e nelle imprese;
- creare ed aggiornare una mappa delle richieste, delle competenze e delle esperienze disponibili sul territorio codificandole in specie digitali (?);
- promuovere attività di informazione dirette alle amministrazioni locali ed alle piccole e medie imprese del territorio regionale, sostenendo modalità di collaborazione tra Università, associazioni ed imprese;
- creare una rete di soggetti, informatici ed utenti impiegati nella PA, utilizzatori privati, sviluppatori, PMI, studenti, collegata agli obiettivi ed alle strategie del Centro di competenza sull’open source (NdR – nel DdL per la verità tale Centro non viene istituito, forse derivato dal testo della L.R. 11/2006 della Regione Umbria che in effetti ha istituito un CCOS);
- contribuire alla individuazione di un adeguato percorso formativo ed universitario, per la preparazione professionale di esperti in software libero, e diretto alle scuole primarie e secondarie per la diffusione di una cultura del software libero;
- confrontare tecnicamente fra loro le architetture dei differenti progetti di sviluppo software per contribuire affinché siano comunque sempre conseguiti gli obiettivi generali di interoperabilità, uso di standard aperti, scalabilità nel tempo e semplicità di riuso da parte delle Pubbliche Amministrazioni;
- promuovere lo studio di fattibilità di sistemi Cloud Computing per la Pubblica Amministrazione tali da poter permettere la distribuzione di risorse di calcolo, archiviazione, software e umane per diversi utilizzatori e scopi.
Gli emendamenti approvati in Consiglio
Durante i lavori della seduta consiliare sono stati inoltre approvati cinque emendamenti, che di fatto vanno a rafforzare l’impianto del testo. Tra i più significativi, il primo fa esplicito riferimento all’open government, come forma di partecipazione attiva dei cittadini al processo decisionale attraverso l’adozione e diffusione degli open data. Il terzo emendamento entra nel merito del Piano d’informatizzazione, con alcuni ulteriori commi inseriti nell’articolo 9 (prima presenti nell’articolo 10, soppressi da un altro emendamento) che opportunamente definiscono in dettaglio i criteri che devono caratterizzare la valutazione tecnica-economica riguardante l’adozione da parte della PA regionale di soluzioni basate su software libero e il loro riuso.
In conclusione, non possiamo che congratularci con la Regione Puglia per l’adozione di questa Legge, che la pone davvero all’avanguardia nella valorizzazione e promozione sia del software libero che degli open data. Il prossimo importante passo sarà la rapida adozione Piano d’informatizzazione, il vero strumento di attuazione della nuova Legge Regionale.
Infine, speriamo ora che il SIT Puglia adegui al più presto le licenze di uso dei dati geografici, rendendoli realmente riusabili in maniera aperta e libera a tutti.
Approfondimenti sul riuso dei dati pubblici
- Comunicazione CE “Dati aperti - Un motore per l’innovazione, la crescita e una governance trasparente” (link)
- EPSIplatform, la piattaforma europea sull’informazione nel settore pubblico (link)
Posted in Dati | 2 Comments »







