Archivio per la categoria ‘Strumenti’
24 agosto, 2016 | di Andrea Borruso
Introduzione
Il GTFS è un formato nato per definire orari e informazioni geografiche legate a reti pubbliche e private di trasporto. E’ nato in sintesi estrema (qui più dettagli) come side project di un dipendente di Google che nel 2005 stava cercando un modo per standardizzare l’importazione di dati di questo tipo in Google Maps. Non c’era ancora uno standard in questo settore, e nel tempo il GTFS è diventato il formato di riferimento, grazie anche all’uso diffuso e alla sua documentazione.
Si tratta di una collezione di file CSV (con estensione .txt) – da un minimo di 6 a un massimo di 13 – archiviati all’interno di un file zip, le cui specifiche sono documentate qui: https://developers.google.com/transit/gtfs/reference/
Per varie ragioni è un formato con cui ho spesso a che fare, ed è stato di ispirazione per creare uno script che ho scritto durante le bellissime olimpiadi di Rio e che ho chiamato GTFS, ready, set, go.
Cosa è GTFS, ready, set, go
È uno script bash che fa essenzialmente una cosa: trasforma i file txt del GTFS in formati pronti per essere usati meglio e subito, sopratutto in applicazioni spaziali. Nel dettaglio:
- scarica una sorgente dati GTFS e ne converte i file
txt in tabelle di un DBMS con estensione spaziale e in particolare in formato spatialite (evviva Alessandro Furieri e tutti quelli che si prendono cura di spatialite);
- trasforma in layer cartografici le tabelle delle fermate e delle rotte (
stops e routes);
- genera alcuna tabelle utili a creare un report sul file della reti di trasporti preso in esame;
- esporta in formato
GeoJSON e KML la tabella delle rotte e quella delle fermate;
- genera un report in formato
HTML e Markdown utili a dare una visione d’insieme dei dati in esame (al momento è ancora minimale e in bozza) .
Nulla di complesso e nulla di nuovo. Ci sono già altre modalità e prodotti per fare cose simili, ma sono scritti in linguaggi che non conosco (ad esempio in Go), richiedono l’installazione di un database server o non spazializzano database sqlite (come il mio amato GTFSDB) o sono procedure (semplici) da svolgere “a mano” e quindi a rischio sempre di qualche errore e con perdite di tempo (come ad esempio questa).
Qui il repository su GitHub: https://github.com/ondata/gtfsreadysetgo
Come funziona
Si tratta di uno script in cui ho messo in fila i comandi utili al mio obiettivo finale, costruendo una (sorta di) macro in cui sfrutto le caratteristiche del bash e alcune utility/applicazioni utili per arrivare al risultato atteso. Queste ultime sono al momento un requisito per lo script, e quindi una piccola barriera ad un utilizzo immediato: le ho utilizzate perché mi hanno consentito di non scrivere “vero” codice, perché “fanno” nella sostanza tutto loro.
Requisiti
Avere un sistema operativo in cui è possibile lanciare uno script bash, quindi ovviamente i sistemi Linux, quelli Mac e anche quelli Windows. Su quest’ultimo apro una piccola parentesi.
Per lanciare uno script bash su Windows – sino a poco tempo fa – era necessario installare “cose” come Cygwin.
Cygwin è una distribuzione di software libero, sviluppata originariamente da Cygnus Solutions, che consente a diverse versioni di Microsoft Windows di svolgere alcuni compiti in maniera esteticamente e funzionalmente simile ad un sistema Unix (da Wikipedia).
Dall’ultimo aggiornamento di release di Windows 10 (l’anniversary update di agosto 2016) è possibile utilizzare nativamente bash anche in Windows, tramite l’applicazione denominata “Bash in Ubuntu on Windows”; “GTFS ready set go” l’ho scritto e testato per intero in ambiente Windows 10, anche per provare questa novità introdotta in questo recente aggiornamento, che rende la comodità e la potenza di fuoco di bash sempre più trasversali.
Lo script sfrutta queste applicazioni:
- GDAL – Geospatial Data Abstraction Library >= 2.1, che viene usato essenzialmente per le operazioni di creazione, importazione e esportazione delle risorse;
- spatialite, che viene sfruttato per fare query spaziali e come uno dei formati di archiviazione e output;
- unzip, per decomprimere il GTFS sorgente;
- curl, per il download del file GTFS;
- csvtk, per convertire in formato Markdown alcune delle tabelle create;
- pandoc, per convertire il report Markdown anche in formato HTML.
E infine vengono utilizzate gli straordinari grep e sed, che sono sempre presenti in ambienti in cui è possibile lanciare uno script bash.
Usare lo script
Questa la modalità attuale di utilizzo:
- scaricare (o clonare) il repository e decomprimere in una cartella il file zip scaricato;
- dare allo script
.sh i permessi di esecuzione;
- aprirlo con un editor di testo e cercare la variabile
URLGTFS;
- sostituire l’URL presente con l’URL di un feed GTFS di proprio interesse (un comodo archivio di GTFS è TransitFeeds) come ad esempio quello di Madrid https://servicios.emtmadrid.es:8443/gtfs/transitemt.zip;
- salvare e lanciare lo script via shell.
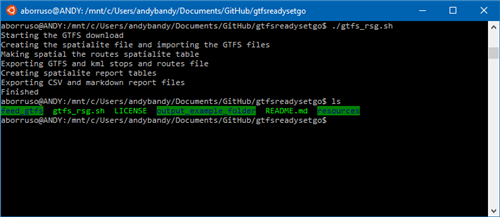
Qui sotto la replica di quanto descritto nei punti di sopra.
Alcune note
Lo script può essere migliorato e di molto. Per questa ragione inserisco alcune importanti note:
- lo script non fa la verifica dei requisiti software (vedi sopra), quindi se non soddisfatti andrà in errore;
- lo script è utilizzabile al momento soltanto con i GTFS che contengono anche la tabella
shapes, che è opzionale per il formato GTFS, quindi non sempre presente;
- lo script non fa alcuna verifica di consistenza dei dati (per la quale è possibile utilizzare FeedValidator;
- lo script crea e cancella file e cartelle nella cartella in cui viene eseguito.
Gli output
Sopra ho già fatto riferimento agli output. Nel repository oltre allo script è stata creata la cartella output_example_folder per mostrare nel concreto quali siano gli output prodotti. A seguire l’elenco dei vari output con i relativi URL, in modo da potersi fare un’idea più concreta:
feed_gtfs.sqlite download, ovvero il file GTFS trasformato in formato SpatiaLite, in cui le tabelle stops e routes sono state trasformate in layer spaziali;routes.geojson (visualizzazione e download), il file in formato GeoJSON per le rotte;routes.kml (download), file in formato KML per le rotte, visualizzabile in Google Earth (ed in altri client);stops.geojson (visualizzazione e download), il file in formato GeoJSON per le fermate;stops.kml (download), file in formato KML per le fermate, visualizzabile in Google Earth (ed in altri client);- la cartella
report(visualizza), che a sua volta contiene:
report.md, il file con il report in formato Markdown (visualizza)report.html, il file con il report in formato HTML (vista codice e rendering HTML);- tutte le tabelle usate per costruire i report, in formato CSV e Markdown.
Perché
GTFS, ready, set, go nasce come conseguenza di #openamat, un’iniziativa civica (ancora in corso) per chiedere a AMAT (la municipalizzata comunale di Palermo che gestisce il trasporto pubblico) di pubblicare i dati relativi ai trasporti pubblici in formato aperto ed in tempo reale.
Dopo 6 mesi senza aggiornare i dati, AMAT ha pubblicato a luglio del 2016 tre aggiornamenti di GTFS in 15 giorni e avevo bisogno di uno script per poter usare e visualizzare subito questi dati.
Lo rendo pubblico perché penso possa essere utile anche ad altri.
URL (che mi sono stati) utili
Posted in Strumenti | 8 Comments »
2 marzo, 2016 | di Andrea Borruso
Da novembre è attivo Transit.land, un progetto sponsorizzato da Mapzen che ha come obiettivo quello di creare un catalogo “integrato” di dati sulle reti di trasporto di tutto il mondo.
Nasce da una sperimentazione fatta a San Francisco, città con più di 30 agenzie di trasporto pubblico, un numero crescente di servizi privati, il carpooling, ecc.. L’obiettivo era proprio quello di mettere a rete tutti questi dati e catalogare le informazioni su autobus, treni, tram, traghetti anche le funivie e renderli interrogabili come se fossero in un unico database.

Tutto talmente bello, che dopo la sperimentazione “locale” è partito il progetto globale, con l’obiettivo di mettere a catalogo file GTFS da tutto il mondo.
La scelta del formato file di input è caduta proprio su General Transit Feed Specification, oggi lo standard di fatto per questo tipo di dati, usato da Google Maps, Microsoft Bing Maps, Apple Maps, ecc. Molti operatori di servizi di trasporto pubblicano i dati in questo formato, e molti innovatori civici hanno creato questi file per le loro città.
Ma si tratta di risorse che per lo più fluttuano nel web spesso come elementi separati. Transitlad, ancora invero in uno stato iniziale, mira a diventare un centro di gravità per questi dataset, completamente aperto in termini di licenza di software e di dati.
Contribuire
Uno dei modi per contribuire al progetto, lanciato da poco, è quello di inviare una nuova sorgente di dati GTFS, in modo che possa essere integrata al catalogo generale, che oggi comprende più di 70 risorse.
Farlo è molto semplice: a partire da questo wizard dove viene richiesto essenzialmente di inserire l’URL della sorgente dati, il tipo di licenza con cui sono pubblicati ed alcune informazioni anagrafiche del mittente.
Il dataset, a quel punto, viene sottoposto ad una verifica e dopo qualche giorno verrà inserito in catalogo.
Un po’ per testare l’oggetto, un po’ perché mi sembra un gran bella idea – non nuova, ma mai pienamente realizzata – mi sono messo all’opera e nel catalogo Trantit.land oggi sono in eleno le “nostre”:
Le API e la “vita” dei dati
I dati, come dice spesso chi fa didattica su questi temi, sono come la farina e l’acqua: materia prima con cui c’è chi farà torte e chi “busiate” (io non ho dubbi).

A Transit.land hanno impastato tutto e invece hanno tirato fuori delle API, rendendo l’interrogazione del loro catalogo un processo semplice, comodo e che potenzialmente potrà produrre diversi effetti a cascata.
Qualche esempio di query:
- Tutte le fermate di un operatore
- Tutte le rotte di un operatore
- Tutte le fermate nel raggio di 500 metri da un punto di coordinate note
- Tutte le fermate comprese in un rettangolo di coordinate note
- Tutte le fermate in cui un certo tag è valorizzato (in questo caso ingresso con sedia a rotelle) in una certa area
- Tutte le fermate che ricadono nella via che ha come OSM ID il valore 395047052 (Corso Vittorio Emanuele a Napoli)
- Tutti i dati su una determinata rotta
- Tutte le rotte comprese in un rettangolo di coordinate note
- Tutti i dati di un oggetto con un determinato Onestop ID
Ma sono solo alcuni esempi e le chiamate disponibili sono molte di più:
https://github.com/transitland/transitland-datastore#api-endpoints
I risultati sono esposti con una paginazione di 50 in 50.
Open Data Day
Sabato 5 marzo 2016 è l’Open Data Day, e una delle sedi sarà la città di Napoli.
Il bello è che sino a 15 giorni fa i dati sui trasporti di questo comune non erano disponibili ed oggi, solo per il fatto di essere stati pubblicati in formato aperto e documentato sono pure accessibili tramite API. Questo è stato possibile grazie anche a Ilaria Vitellio che si è spesa personalmente con la pubblica amministrazione locale, che ha risposto prontamente ed ha pubblicato questi dati.
In bocca al lupo allora a Ilaria ed a tutti i presenti a Napoli, che avranno a disposizione nuova farina e nuovi mattarelli.
In chiusura una nota personale. Anche i dati sulla mia città, Palermo, sono presenti nel catalogo e quindi accessibili via API, ma purtroppo valgono per fare qualche demo di qualità.
Si tratta di dati aggiornati a fine dicembre, in cui non è contemplata la nuova rete tranviaria e tutti i grossi cambiamenti che la rete ha subito tra fine 2015 e inizio 2016.
E’ un fatto grave, specie per una città ricca di turisti come Palermo e con grossi problemi di traffico autoveicolare, che non siano ancora disponibili dati aggiornati sui trasporti pubblici.
Ne riparlerò in un altro post.
Posted in Strumenti | 5 Comments »
8 febbraio, 2016 | di guest
NdR: questa è la seconda parte del post pubblicato qui.
Impostazione lato server: ona.io
Giuseppe: Proponiamo di partire da qui, dal “lato server”, dal momento che è la prima cosa che si va a vedere perché bisogna registrarsi: https://ona.io/join
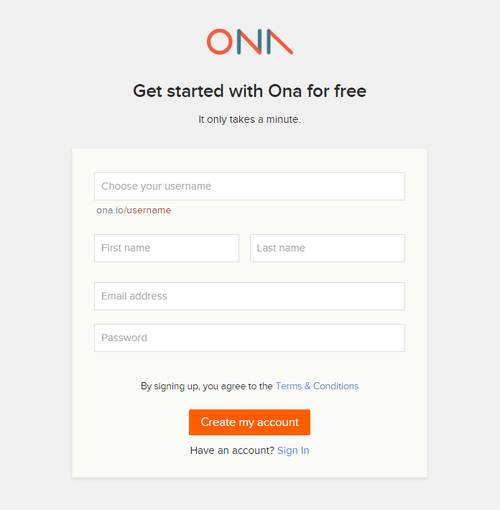
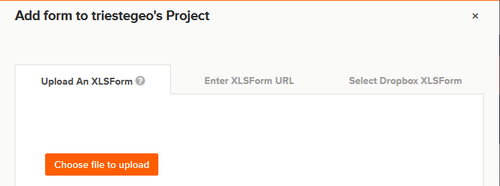
Una volta registrati, si può impostare un nuovo progetto e scegliere il livello di ‘privacy’. La pagina iniziale è la seguente (con il nome che avete scelto al posto di triestegeo, ovviamente).
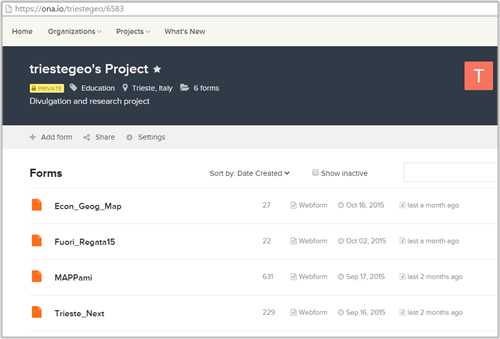
Dal sito alla voce ‘add form’ è possibile caricare il questionario/form impostato come file XLS, che nelle righe sotto vi spieghiamo come preparare.
Le ‘form’ saranno i questionari e la scheda di acquisizione dati, che successivamente verrà visualizzata sul vostro smartphone o tablet.
Sarà possibile preparare più progetti e specificare il livello di ‘privacy‘, ovvero se progetto ‘pubblico’ o ‘privato’. Ona.io consente diverse possibilità: nel caso di un profilo ‘pubblico’ non vi sono fee da pagare, mentre per alcuni profili privati o con più restrizioni all’utilizzo, è prevista una quota da versare.
Il ‘lato server’ sarà il ‘contenitore’ dei dati, il luogo dove questi saranno conservati una volta caricati, e dove sarà possibile effettuare delle operazioni, quali visualizzazione tabulare o sotto forma di mappa, dove sarà possibile caricare eventuali file multimediali (come ad esempio immagini o video registrati) nonché dei report sulle attività (es. delle statistiche sulle acquisizioni di dati, ecc.) e scaricare i dati in vari formati una volta raccolti.
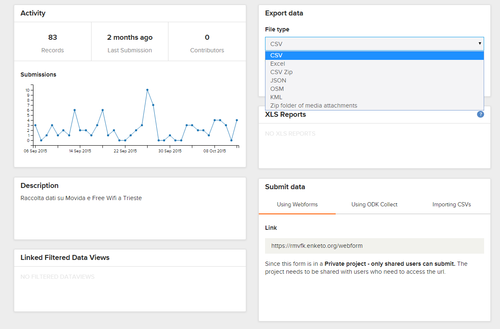
Dal ‘lato server’ è possibile anche accedere alla WebForm, ovvero dalla finestra (su pagina web) da cui caricare i dati (qualora non si disponga di un dispositivo mobile adatto).
Ovviamente il passaggio necessario, prima di tutto ciò, è l’impostazione del questionario o form, ovvero il ‘cuore’ di tutto il sistema di raccolta dati!
Impostazione del questionario/form con un file Excel
Viola: la form contenente il questionario da caricare sul server per cominciare la raccolta è un file Excel (quindi con estensione .xls) che deve essere formato obbligatoriamente da due fogli di lavoro, denominati ‘survey’ e ‘choices’, cui si può affiancare a discrezione dell’utente un ulteriore foglio di lavoro rinominato ‘settings’. Nel foglio ‘survey‘ c’è la griglia di domande e informazioni da raccogliere, impostate in ordine ben preciso. Sono presenti varie colonne, di cui le principali (ed obbligatorie) sono:
In ‘type’ si individua il tipo di inserimento (output) richiesto all’utente che compila la form relativa ad ogni domanda: testo, orario, numeri interi, coordinate, selezionare una o più opzioni da una scelta di risposte, coordinate GPS, immagini, audio, video e così via.
| Nel foglio di lavoro rinominato “survey”.Possibili tipologie di output richiesti all’utente da specificare nella colonna ‘type’ |
| Text |
Testo |
| Integer |
Numeri interi |
| Decimal |
Numeri decimali |
| select_one [nome della lista di possibili risposte, che si esplicitano nel secondo foglio]es. select_one affluenza_evento |
Per le domande a risposta multipla, dove è possibile selezionare solo una riposta |
| select_multiple seguito dal nome della lista di possibili risposte che si esplicitano nel secondo foglio]es. select_multiple nome_wifi |
Per le domande a risposta multipla dove si consente di selezionare varie risposte |
| Note |
È un campo che non ha bisogno di input da parte dell’utente, è una schermata normalmente utilizzata all’inizio o alla fine della survey per presentare il questionario o per ringraziare l’utente per l’inserimento |
| Geopoint |
Rileva le coordinate GPS |
| Geotrace |
Rileva le coordinate di una polinea |
| Geoshape |
Rileva le coordinate di un poligono |
| Image |
Si chiede all’utente di caricare o scattare una foto |
| Barcode |
Permette di leggere un codice a barre qualora sia installata sul telefono una applicazione in grado di leggere il codice. |
| Date |
Rileva la data in automatico |
| Datetime |
Permette di rilevare data e ora della compilazione del questionario in automatico |
| Audio |
Si può registrare un audio |
| Video |
Si richiede di fare un video o caricarlo dalla galleria |
| Calculate |
Permette di fare un calcolo |
Nella colonna ‘name‘ si inserisce un nome con cui poter identificare la singola domanda, specificata poi per esteso come si vuole venga visualizzata nella compilazione del questionario colonna ‘label’. I dati verranno visualizzati con questo nome identificativo quando li si andrà a sfogliare dal sito internet.
Qualora si vogliano porre domande con risposte già preimpostate, è necessario inserire “select_one” se l’utente ha la possibilità di selezionare solo una risposta, oppure “select_multiple” se può sceglierne più di una, seguito dal ‘nome’ che identifica il gruppo di domande. Nel nostro caso si era deciso di avere informazioni sull’affluenza all’evento o nel locale di riferimento, con possibilità di scegliere tra ottima, buona, discreta o scarsa, e per quanto riguarda la presenza di free wifi si poteva di selezionare tra le due reti pubbliche, Eduroam e TriesteFreeSpots, oppure la presenza di una rete aperta del locale in cui ci si trova.
Spesso le immagini valgono più di mille parole e quindi guardate un po’ come abbiamo impostato noi il primo foglio di lavoro.
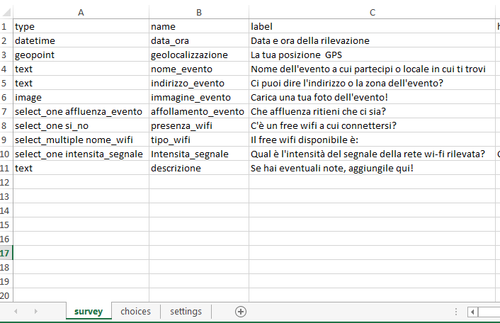
Il campo ‘type’ per inserire il ‘datetime’ o solo ‘time’ o ‘date’ per permettere di capire gli orari e le date in cui si compila il questionario è molto comodo perchè questa informazione viene rilevata in maniera automatica.
Nel momento in cui si inserisce ‘geopoint’ per rilevare la propria posizione GPS, l’operazione può richiedere anche un paio di minuti (all’inizio) per essere abbastanza accurata, è normale. Se avete fretta, potete attendere che il fumetto vi dia indicazioni sulla precisione della rilevazione, cliccare su Registra Localizzazione e continuare a compilare il modulo fino a salvarlo; poi l’applicazione permette di modificare in seguito la posizione semplicemente spostando un puntino sulla mappa andando su “Edit data”.
È possibile anche impostare delle domande concatenate con una delle domande precedenti, ma questa funzione è stata assimilata solo dopo. Esempio: nel nostro caso era possibile fare le domande in riga 9 e 10 di specificazione su nome e copertura wi-fi solo se prima l’utente aveva selezionato ‘si’ alla domanda in riga 8, che richiedeva di dire se c’era un free wi-fi nelle vicinanze. Bisognava allora inserire una colonna denominata ‘Relevant’ accanto a ‘Label’ in corrispondenza di tali righe con campo ${si_no} = ‘si’, dove $ sta per ‘selected’ seguito tra parentesi graffe il nome della lista di risposte relative alla domanda (nel nostro caso si_no) seguito da un simbolo di “uguale” (‘=’) e dalla risposta tra apici singoli (”).
Nel secondo foglio di lavoro vanno inserite le griglie di risposte possibili alle varie domande a risposta multipla: il link con il primo foglio è dato dal nome della lista delle risposte inserito nella colonna ‘type’ dopo la dicitura select_one (oppure multiple), che viene ripetuto nel secondo foglio in prima colonna, chiamata ‘list name’.
È utile anche perché è possibile così evitare di riscrivere opzioni di risposta inserite già in altre liste, potendo riferirsi alla stessa: il più semplice esempio è dato dalle risposte come “si” o “no”. Se la lista di risposte si chiama si_no, è possibile inserire due domande del tipo select_one [si_no], con nome ed etichetta diverse, scrivendole nel foglio choices una volta sola.
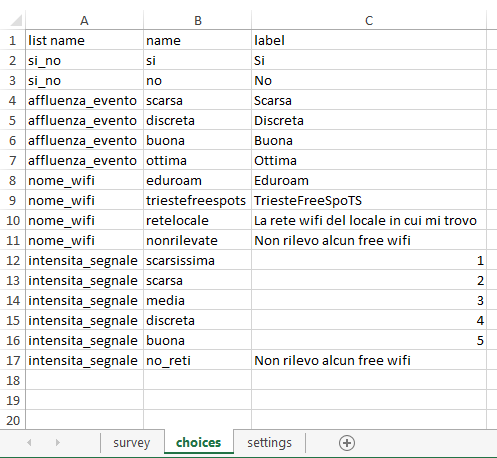
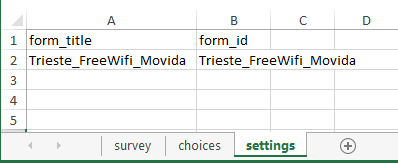
A questo punto, se si vuole è possibile aggiungere un altro foglio denominato ‘settings‘, dove inserire due colonna, ‘form_title’ e ‘form ID’, tramite cui è possibile denominare il questionario: in assenza il questionario avrà lo stesso nome dato al file xls che verrà caricato sul sito.
Giuseppe: Il terzo componente del sistema è quello ‘mobile‘, ovvero relativo alla raccolta vera e propria dei dati.
Una volta scaricata l’applicazione GeoODK Collect, ricordiamoci che è solo nel Play Store, la schermata iniziale è la seguente.

Per partire con la raccolta bisogna modificare le impostazioni preimpostate e caricare la form che ormai abbiamo già messo sul server. E’ necessario innanzitutto premere l’icona delle impostazioni (Settings) e poi General Settings, selezionare ‘altro server’, modificando l’URL preesistente con il server utilizzato per caricare i dati sul web, https://ona.io/nome_progetto/.
Tornando nelle impostazioni precedenti è necessario poi cliccare su ‘form management’, dove compariranno tutte le form create dal proprio account nel server e selezionare quella che ci interessa. Dopo aver premuto “prendi selezionato” e aver dato l’invio cliccando su “ok”, si ha in memoria la form “vuota” e si possono raccogliere i dati andando sull’icona ‘collect data’ e selezionando la form appena scaricata.
La app dà la possibilità di fare una serie di operazioni: modificare i dati delle form già compilati e salvati (edit data), spostare la posizione dei rilevamenti qualora non fossero abbastanza accurati, eliminare form (delete data) e, infine, inviare i dati al server (send data). Quest’ultima operazione è quella che ‘vuota’ dei dati il nostro dispositivo mobile: ricordiamo, infatti, che l’iniziativa ODK nasce per scopi ‘sociali’ e umanitari, ed è pensata pertanto per raccogliere dati anche in assenza di una copertura di rete, con pertanto la possibilità di inviare i dati soltanto una volta in cui questa sia resa disponibile.
Viola: Gli stessi dati possono essere raccolti anche tramite una webform, ovvero una pagina web dove sono riportate i medesimi quesiti della form, solo organizati ovviamente con un layout diverso. Perché usare questo strumento anziché l’app? per 3 motivi:
- Per i pigri che non vogliono installare l’app ma operare da browser;
- Per i possessori di dispositivi non-Android (Windows Phone e iPhone)
- Più semplicemente per chi ha magari acquisito dei dati ‘su carta’ e vuole ‘buttarli dentro’ a una banca dati comodamente seduto alla scrivania.
Attenzione che però non tutti i browser funzionano bene! Se vi interessa acquisire immagini, video o audio ci sono alcune limitazioni: serve il browser Chrome, se poi avete un iOS potete averle solo tramite un browser che si chiama Puffin! Comunque la rilevazione di tutti gli altri campi sarà possibile 
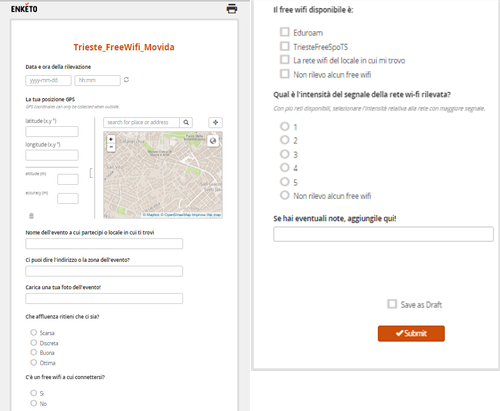
Giuseppe: Se siete curiosi di provare GeoODK e a inserire qualche dato, provate con il progetto ‘Trieste Free Wifi Movida’! Si è concentrato sulla città di Trieste e per ora è terminato (Viola ha finito la tesi di laurea magistrale, e quello era l’oggetto della ricerca!), però potete provare a inserire dei dati sul wifi e sull’affollamento dei locali nella vostra città (magari mandateci un’email così mostriamo qualche elaborazione!). Potete farlo tramite la webform su Enketo qui sotto:Anche in questo caso è possibile sia inviare i dati immediatamente (‘submit‘ a fine acquisizione) o rimandare in un secondo tempo (e selezionare ‘save as draft‘).
https://rmvfk.enketo.org/webform
Oppure, dopo essersi installati GeoODK, andare su “Settings”, sotto “General Settings” scegliere il server “Altro” e inserire https://ona.io/triestegeo.
Su “Form Management” (sempre sotto ‘settings’) selezionare la form “Trieste_FreeWiFi_Movida”
A questo punto è possibile raccogliere dati e inserirli nel database creato per questa form (ovviamente la procedura sarà la medesima quando avrete creato il vostro progetto in Ona e caricato una o più form)!
La nostra Viola ha preparato anche un video su Youtube con una panoramica su come impostare la form su GeoODK e iniziare ad acquisire i dati! https://www.youtube.com/watch?v=EP2PA5ysyEk
Altre applicazioni
Viola: Questa applicazione è stata utilizzata anche per raccogliere dati sull’affluenza a due eventi cittadini, TriesteNext (weekend dedito alla divulgazione scientifica e dimostrazioni nell’ambito accademico organizzati dall’Università di Trieste) e FuoriRegata (serie di eventi lato terra che si svolgono la settimana precedente alla Barcolana). Con uno stand di ‘geografi’ capeggiati dal qui presente Giuseppe, sempre a Trieste Next 2015, abbiamo poi presentato due attività permesse dalla customizzazione di questa applicazione: una per ‘mappare’ la provenienza dei visitatori a Trieste Next e un’altra per la mappatura delle zone problematiche legate all’accessibilità e alle barriere architettoniche della città di Trieste.

Appena pronti vi segnaleremo i collegamenti ai lavori che sono stati realizzati su questi progetti!
Conclusioni – altri sviluppi
Per i nostri progetti di mobile data collection abbiamo scelto la base di Open Data Kit per strutturare il sistema di raccolta dati, accompagnato all’app per dispositivo mobile GeoODK. In realtà GeoODK non è l’unica app che lavora in questo sistema. ODK Collect e Kobo sono due app che si basano sulla medesima architettura per la raccolta dei dati, consentendo anche la gestione di dati geolocalizzati.
(https://play.google.com/store/apps/details?id=org.odk.collect.android&hl=it; https://play.google.com/store/apps/details?id=org.koboc.collect.android&hl=it)
L’unico problema in questi due esempi è dato dal fatto che solo dati puntuali possono essere acquisiti durante una ‘campagna’ e possono essere visualizzati e modificati solo dopo averli scaricati su server.
Nel caso di GeoODK invece funzioni di visualizzazione e di editing dei dati possono essere fatte già da dispositivo mobile prima di caricarli sul server.
Un altro elemento importante, che tuttavia stiamo appena testando, è dato dal fatto che GeoODK consente di acquisire dati anche sotto forma di polilinea o poligono, oltre che punti (v. sopra il riferimento alle funzioni Geopoint, Geotrace e Geoshape). In questo caso, tuttavia, al momento le soluzioni lato server come ona.io non supportano la gestione di tale dato, per cui si rende necessario installare localmente ODK Aggregate, ovvero il server di aggregazione dei dati da dispositivo mobile. Siamo in fase ‘work in progress’ anche noi, speriamo di riuscire a testare anche questa soluzione!
Per qualsiasi approfondimento non esitate a contattarci! Saremo felici di rispondere e approfondire gli argomenti!
 Nasco geografo economico, mi interesso di Geographic Information e di Smart Cities. Attratto dalle tecnologie ICT e dall’innovazione, ma sempre con l’uomo al centro. Professore di Economic Geogrphy, GIS e Geografia delle Reti. Presidente del Comitato Scientifico dell’Associazione Italiana di Cartografia. Nel tempo libero, poco, running o MTB
Nasco geografo economico, mi interesso di Geographic Information e di Smart Cities. Attratto dalle tecnologie ICT e dall’innovazione, ma sempre con l’uomo al centro. Professore di Economic Geogrphy, GIS e Geografia delle Reti. Presidente del Comitato Scientifico dell’Associazione Italiana di Cartografia. Nel tempo libero, poco, running o MTB
 Fresca fresca di laurea magistrale in Scienze Aziendali, ho scoperto “all’ultimo minuto” una passione per Smart Cities, GIS e Citizen science, di cui ho scritto per il lavoro di tesi. Sono fermamente convinta che non esistano Smart Cities senza Smart Citizens e che la tecnologia sia un mezzo e non un fine per migliorare le città.
Fresca fresca di laurea magistrale in Scienze Aziendali, ho scoperto “all’ultimo minuto” una passione per Smart Cities, GIS e Citizen science, di cui ho scritto per il lavoro di tesi. Sono fermamente convinta che non esistano Smart Cities senza Smart Citizens e che la tecnologia sia un mezzo e non un fine per migliorare le città.
Posted in Strumenti | No Comments »
21 gennaio, 2016 | di guest
Giuseppe: Oggi parliamo tanto di “cittadini sensori“, di Citizen Science, di crowdsourcing e, in poche parole, del coinvolgimento attivo da parte dei cittadini in progetti di raccolta dati (georeferenziati) sul terreno, per progetti di ricerca o di pubblica utilità.
Sappiamo che tali iniziative sono possibili in misura sempre maggiore grazie a delle “rivoluzioni” che ci hanno coinvolto molto da vicino e relativamente molto recenti. L’aumento della velocità di trasmissione dati su Internet, l’abbassamento dei costi legati alle tecnologie ICT, la disponibilità di sistemi di localizzazione GNSS (GPS e altri) a basso costo e di buona precisione (almeno per applicazioni diverse da quelle geodetiche!) e lo sviluppo di smartphone e Social Network hanno senz’altro reso più facile e veloce l’interazione tra individui dotati di dispositivi “smart”, tra loro e con piattaforme di condivisione di dati e informazioni.
Questo è senz’altro vero, ma iniziare a raccogliere dati geolocalizzati in maniera ordinata e sistematica e c ondividerli alla fine del processo richiede nella maggior parte dei casi un po’ di doti di programmazione o quanto meno di familiarità avanzata con strumenti di tipo informatico.
Tale premessa è alla base di quanto abbiamo cercato di sviluppare, a partire dall’estate del 2015, con i ragazzi dell’insegnamento di Geografia delle Reti, nell’ambito dei Corsi di Laurea Magistrali in “Scienze Economiche” e “Scienze Aziendali ” dell’Università di Trieste.
L’idea di partenza era quella di sperimentare modalità di crowdsourcing nell’acquisizione di dati geografici relativi a fenomeni urbani su piattaforme una soluzione senza costi di licenza e con un limitato ricorso a doti di programmazione.
Viola: Oltre ad una soluzione a basso costo e di relativa semplicità nell’impostazione del questionario, volevamo uno strumento che, oltre
a poter registrare dati sotto forma di punti, polilinee o poligoni, avesse queste caratteristiche:
- relativa applicazione scaricabile (gratuitamente) su smartphone;
- permettesse la compilazione del questionario anche in caso di assenza di rete;
- permettesse di caricare un numero molto elevato di risposte da vari dispositivi (o comunque un numero in linea con le nostre esigenze);
- fosse compilabile via sito web (in caso di problemi di compatibilità con il sistema operativo del telefono o in presenza di qualche buon’anima ancora dotata di Nokia 3310 come arma di battaglia!)
Potrebbero sembrare delle premesse un po’ pretenziose ma dopo varie ricerche, qualche decina di download (wi-fi permettendo) a causa di una rete casalinga un po’ ballerina, qualcosa abbiamo trovato.
Ci siamo imbattuti nella “galassia” di Open Data Kit, un progetto “open” che consente l’impostazione di sistemi client-server di raccolta
e archiviazione di dati da parte di operatori sul campo tramite dispositivi mobili.
Dal sito (https://opendatakit.org/) si legge che ODK (dove ODK sta per Open Data Kit, nel caso ve lo stiate chiedendo) è un “free and open-source set of tools which helps organizations author, field, and manage mobile data collection solutions“, che consente di:
- costruire una form (o “questionario”) di raccolta dati;
- raccogliere dati su di un dispositivo mobile;
- aggregare i dati raccolti su di un server ed estrarli in formati utilizzabili.
Giuseppe: Open Data Kit inizialmente si è sviluppato basando su Google la gestione del proprio “lato server”, dopodiché si è affrancato dal mondo ”commerciale” basandosi soprattutto su architetture open source.
Il sistema richiede diversi elementi, esemplificati nell’immagine qui sotto, da integrare.
Innanzitutto una form, ovvero il questionario da sviluppare.
Una ‘piattaforma’ per la raccolta dei dati: qui ci viene in aiuto enketo.org per la realizzazione di una webform compilabile da (virtualmente) qualsiasi dispositivo, oppure un’app da caricare su dispositivo mobile. Diverse app sono state sviluppate: ODK Collect e KoBo Collect, solo per citarne un paio, soprattutto nell’ambito di progetti a contenuto umanitario o sviluppati apposta per scopi educativi.
Un server, ovvero un sistema centralizzato in cui salvare i dati immessi. Senza ricorrere a un nostro server si può fare riferimento alle piattaforme ODK aggregate e Ona.io.
Viste le applicazioni alternative basate sulla stessa base ODK, abbiamo scelto GeoODK perché ci è sembrata la più semplice e completa, perché consente anche la modifica dei dati prima dell’upload su una base cartografica digitale e di caricare sul dispositivo dei layer geografici ad hoc (non necessariamente le basi di sfondo tipo OpenStreetMap) – funzionalità non implementata nell’esempio che abbiamo riportato in questo report.
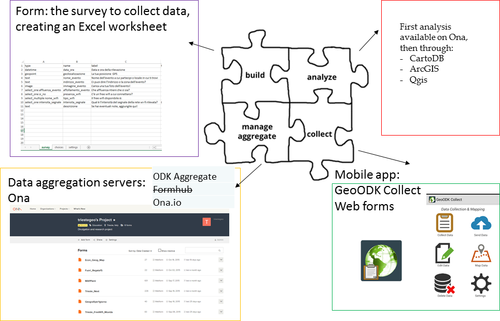
Il Sistema ODK (Open Data Kit) e le sue componenti
Inutile dire che, per i nostri scopi, l’attenzione era rivolta alla raccolta di dati georeferenziati, sfruttando il GPS interno per geolocalizzarsi. Il
sistema ‘ODK’ offre numerose app già pronte utili per la raccolta dei dati, come ODK Collect e KoBo collect. Queste tuttavia consentono soltanto di caricare dati geografici sotto forma di punti (coppie di coordinate) e hanno un’interfaccia molto semplice e tutto sommato limitata, senza grandi possibilità di editing e visualizzazione dei dati sul dispositivo mobile.
Viola: L’applicazione scelta è stata GeoODK, dove il “Geo” sta per Geographical (Open Data Kit), sviluppata sempre a partire dalla piattaforma ODK, ma con un’attenzione maggiore al lato geografico.
In particolare consente varie cose in più rispetto a ODK, ovvero:
- è più semplice;
- consente di visualizzare e modificare i dati prima dell’upload su una base digitale sullo smartphone o tablet;
- consente di caricare localmente dei layer geografici ad hoc (non necessariamente le basi di sfondo tipo OpenStreetMap) – funzionalità non implementata nell’esempio riportato;
- consente di registrare, anche tramite form, dati sotto forma di punti, polilinee o poligoni (funzioni “geopoint”, “geotrace” e ”geoshape”).
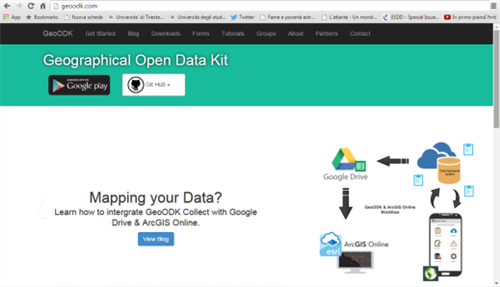
GeoODK permette di strutturare un questionario tramite un semplice file Excel (se vedete la parola “form” più avanti non vi spaventate, ci riferiamo a questo) e qualche piccola accortezza, fornendo già sia la propria applicazione mobile sia una soluzione “lato server” per l’aggregazione dei dati, individuata inizialmente in Formhub, dopodiché (a causa della sua lentezza e dell’abbandono da parte degli sviluppatori) trovata nella piattaforma ona.io (anche questa in seguito non più disponibile completamente free). L’alternativa “locale” rimane sempre ODK Aggregate, da installare su di un proprio server.
Mentre la seconda soluzione è più laboriosa, richiedendo di caricare ODK Collect sul proprio server (per il momento ci stiamo pensando ma non abbiamo ancora messo in pratica di sfruttare il server dell’Università di Trieste e il nostro adorato informatico A.P.), Formhub era già bello e pronto e richiedeva solo l’iscrizione (ovviamente gratuita) dell’utente. Problema incontrato già al momento della scelta di utente e password: il server faceva venire i sudori freddi. Era in sovraccarico un buon 70-80% delle volte in cui ci si connetteva e si aveva bisogno di lui. Qualche settimana fa poi il server non è definitivamente più aggiornato dall’organizzazione che se ne occupava quindi ve lo sconsigliamo proprio.
Il sito web http://geoodk.com/tutorials.php contiene un buon videotutorial su come impostare i diversi elementi di un progetto di Mobile Data Collection, presentati al GIS Day 2014. Da quello siamo partiti per il nostro lavoro, e qui sotto cerchiamo di sintetizzarlo un po’ a un pubblico italiano.
Dopo un paio di mesi di stress ed incubi causati dai continui problemi di sovraccarico di Formhub, a settembre il magico prof (Giuseppe) ha trovato un nuovo server su cui caricare i dati. Stesso layout di Formhub, stesse funzioni… la copia conforme ma rapidissima: Ona.io.
Così, un’altra registrazione più in là siamo finiti su un altro server felici e contenti come pasque. Escludendo il fatto che il primo ottobre hanno rilasciato una nuova piattaforma dal diverso layout per cui abbiamo avuto entrambi un colpo al cuore…temevamo di aver perso tutto!
In realtà abbiamo scoperto che dal 21 ottobre cambiano i termini di utilizzo e, in verità, il sito è stato migliorato e con le attuali condizioni è possibile avere un account gratuito caricando fino a 15 questionari e ricevendo fino a 500 risposte al mese, che tutto sommato – poi dipende dall’uso che si vuole fare- sono un buon numero.
LA SETTIMANA PROSSIMA IL SEGUITO …
Nasco geografo economico, mi interesso di Geographic Information e di Smart Cities. Attratto dalle tecnologie ICT e dall’innovazione, ma sempre con l’uomo al centro. Professore di Economic Geogrphy, GIS e Geografia delle Reti. Presidente del Comitato Scientifico dell’Associazione Italiana di Cartografia. Nel tempo libero, poco, running o MTB
Fresca fresca di laurea magistrale in Scienze Aziendali, ho scoperto “all’ultimo minuto” una passione per Smart Cities, GIS e Citizen science, di cui ho scritto per il lavoro di tesi. Sono fermamente convinta che non esistano Smart Cities senza Smart Citizens e che la tecnologia sia un mezzo e non un fine per migliorare le città.
Posted in Strumenti | 1 Comment »
31 luglio, 2015 | di Andrea Borruso
Il 18 giugno 2015 è stata rilasciata la versione 2.0.0 di GDAL/OGR. Una delle novità è legata a un nuovo driver di OGR “Catalog Service for the Web (CSW)”, che consente di accedere a cataloghi di risorse cartografiche esposti sul web.
La sintassi di base per leggere le informazioni da queste fonti è:
ogrinfo -ro -al -noextent CSW:http//catalogo.it/csw
L’utility di riferimento è ogrinfo, e sono a disposizione quindi tutte le altre opzioni del comando.
I cataloghi CSW sono un po’ come quei cassetti pieni di calzini in cui, in occasione di una importante ricorrenza, cerchiamo quelli lilla a pois bianchi (sono an pendant con l’ultima nostra meravigliosa giacca), ma per troppa abbondanza e varietà non riusciremo mai a trovare. Bisogna anche saper cercare 
OGR è l’ultimo arrivato tra gli strumenti di accesso e ricerca. Ecco qualche semplice esempio, basato sul catalogo del Repertorio Nazionale dei Dati Territoriali (RNDT).
Avere l’elenco di tutti i record del server
ogrinfo -ro -al -noextent CSW:http://www.rndt.gov.it/RNDT/CSW -oo MAX_RECORDS=100
Sul catalogo RNDT sono presenti più di 17000 record, quindi la risposta al comando sarà “lunga”. L’opzione MAX_RECORDS fissa il numero massimo di record che è possibile ricevere ciclicamente durante una chiamata. Nell’esempio di sopra, per 17000 record quindi 170 cicli, ognuno composto da 100 record di output.
Tutti i record all’interno di una determinata area
ogrinfo -ro -al -noextent CSW:http://www.rndt.gov.it/RNDT/CSW -spat 12 35 15 38 -oo MAX_RECORDS=100
Ogni record di un catalogo CSW è associato ad un’estensione geografica. Inserendo il parametro -spat si impostano le coordinate del boundig box (xmin ymin xmax ymax, in EPSG:4326) all’interno del quale si vuole eseguire la ricerca: in risposta si avranno tutti i record ricadenti in quell’area.
Tutti i record che contengono una determinata parola (stringa di testo) in uno dei campi esposti dal catalogo
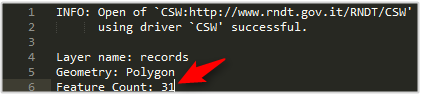
ogrinfo -ro -al -noextent CSW:http://www.rndt.gov.it/RNDT/CSW -where \"abstract LIKE '%geologia%'\" -oo MAX_RECORDS=100
In questo modo si cercheranno tutti i record che contengono la parola “geologia” nel campo “abstract”. Ad oggi sono 31.
Gli altri campi che è possibile sfruttare per fare ricerche sono:
- identifier (String)
- other_identifiers (StringList)
- type (String)
- subject (String)
- other_subjects (StringList)
- references (String)
- other_references (StringList)
- modified (String)
- abstract (String)
- date (String)
- language (String)
- rights (String)
- format (String)
- other_formats (StringList)
- creator (String)
- source (String)
Tutti i record che contengono una determinata stringa in un campo qualsiasi
ogrinfo -ro -al -noextent CSW:http://www.rndt.gov.it/RNDT/CSW -where \"anytext LIKE '%frane%'\" -oo MAX_RECORDS=100
La stringa cercata è “frane”, e si ottengono 52 record.
ogrinfo -ro -al -noextent CSW:http://www.rndt.gov.it/RNDT/CSW -where \"anytext LIKE '%frane%'\" -oo OUTPUT_SCHEMA=gmd -oo MAX_RECORDS=100
L’output in questo caso è secondo lo schema descritto qui http://www.isotc211.org/2005/gmd. Se invece si scrive OUTPUT_SCHEMA=csw, sarà secondo queste specifiche http://www.opengis.net/cat/csw/2.0.2.
Tutte le altre novità su GDAL/OGR 2.0.0 le trovate sintetizzate nel post di Even Rouault e purtroppo il catalogo RNDT non è ancora nel registro INSPIRE! 
Posted in Strumenti | 2 Comments »







