29 aprile, 2010 | di Pietro Blu Giandonato
La Banca Mondiale , come molti sapranno, fornisce prestiti agevolati ai paesi in via di sviluppo per finanziare programmi volti alla riduzione della povertà. Come spesso accade, non è tutto oro quello che luccica, e infatti da molti anni è stata lanciata una campagna internazionale per la sua riforma.
Ma non è dei lati oscuri che ogni banca ha – e ai quali nemmeno la World Bank sfugge – che voglio parlare qui oggi, ma della decisione di liberare i dati che questa istituzione detiene, e che riguardano i Paesi di tutto il mondo. Le attività di ricerca e finanziarie che la Banca svolge, si basano infatti su dati di tipo demografico, produttivo e ambientale di assoluto valore, e la decisione di renderli disponibili è un grande passo verso l’idea di dati “grezzi, aperti e liberi”.
Come fa presente Andrew Turner in un suo recente post, la Banca Mondiale aveva da tempo rilasciato delle API per poter utilizzare la propria banca dati in applicazioni esterne (c’è perfino un’app per iPhone), ma poterli ora scaricare in formati aperti (CSV, XML) li rende davvero accessibili a chiunque, per qualunque scopo.
Il catalogo dei dati è consultabile direttamente sul sito della WB, per Paese (qui l’esempio relativo all’Italia) con la possibilità di visionare direttamente in una stessa pagina i trend dei classici indicatori finanziari (PIL, export, reddito pro-capite, ecc.), demografici (indice alfabetizzazione, disoccupazione, educazione), sanitari (mortalità) e ambientali (produzione CO2 pro-capite). Ogni singolo dataset è poi scaricabile, come detto, in formati aperti utilizzabili in qualunque applicazione e per qualunque scopo.

Dati grezzi, aperti e liberi… a livello mondiale!
Posted in Dati | No Comments »
10 agosto, 2009 | di Pietro Blu Giandonato
Era un pezzo che desideravo sperimentare Yahoo Pipes , dopo esserne venuto a conoscenza grazie ad Andrea (ricorderete il suo precedente geniale post). In effetti ho giocato d’anticipo proprio su di lui, per cimentarmi a produrre un GeoRSS in puro stile web 2.0.
Non ho certo intenzione di mettermi qui a tessere le lodi di Pipes, sebbene a mio avviso non se ne parli mai abbastanza. Voglio solo ribadire che si tratta di uno strumento web 2.0 dalle potenzialità pressoché infinite, che aumentano esponenzialmente in funzione della crescente messe di risorse e fonti di dati disponibili sul web. A patto che, inutile dirlo, lo siano secondo standard aperti, come già Andrea ha molto ben sottolineato proprio nel suo citato articolo.
Passiamo ai fatti.
Un item GeoRSS, nella codifica W3C ha la seguente struttura:
<?xml version=\"1.0\"?>
<?xml-stylesheet href=\"/eqcenter/catalogs/rssxsl.php?feed=eqs7day-M5.xml\" type=\"text/xsl\"
media=\"screen\"?>
<rss version=\"2.0\"
xmlns:geo=\"http://www.w3.org/2003/01/geo/wgs84_pos#\"
xmlns:dc=\"http://purl.org/dc/elements/1.1/\">
<channel>
<title>USGS M5+ Earthquakes</title>
<description>Real-time, worldwide earthquake list for the past 7 days</description>
<link>http://earthquake.usgs.gov/eqcenter/</link>
<dc:publisher>U.S. Geological Survey</dc:publisher>
<pubDate>Thu, 27 Dec 2007 23:56:15 PST</pubDate>
<item> <pubDate>Fri, 28 Dec 2007 05:24:17 GMT</pubDate> <title>M 5.3, northern Sumatra, Indonesia</title> <description>December 28, 2007 05:24:17 GMT</description> <link>http://earthquake.usgs.gov/eqcenter/recenteqsww/Quakes/us2007llai.php</link> <geo:lat>5.5319</geo:lat> <geo:long>95.8972</geo:long> </item>
</channel>
</rss>
L’obiettivo è costruire un GeoRSS a partire da una fonte di dati che viene aggiornata in tempo reale, nella fattispecie – e tanto per essere originali – l’elenco dei terremoti rilevati dal Centro Nazionale Terremoti dell’INGV, sul cui sito vedrete una pagina html con tutti gli ultimi eventi rilevati.
Per il nostro lavoro utilizzeremo sempre le stesse informazioni, ma in formato standard CSV – disponibili qui – dunque perfettamente importabili pressochè ovunque. Vediamone i contenuti:
- Lat – la latitudine dell’evento in gradi decimali;
- Lon – la longitudine dell’evento in gradi decimali;
- Depth – la profondità dell’ipocentro in km;
- UTC_Date – il momento temporale nel quale l’evento è stato registrato;
- Magnitude – la magnitudine Richter dell’evento;
- Locality – il distretto sismico nel quale è avvenuto il terremoto;
- Code – un codice univoco relativo all’evento;
- Query_Time – il tempo di query del file CSV, corrispondente a quello di caricamento della pagina del sito INGV.
In Pipes, il primo passo consiste nell’andare a recuperare (fetch) la fonte dei dati (il file CSV) per poterne poi utilizzare il contenuto. Verrà utilizzato il modulo “Fetch CSV” nel quale andremo ad inserire l’URL del CSV, usando la prima riga come intestazione delle colonne.
 Per poter generare il GeoRSS, Pipes deve “vedere” nei dati recuperati elementi che siano chiaramente riferibili a una coppia di coordinate, pertanto rinomineremo i campi “Lat” e “Lon” del CSV nei prosaici “Latitude” e “Longitude” mediante il modulo “Rename”.
Per poter generare il GeoRSS, Pipes deve “vedere” nei dati recuperati elementi che siano chiaramente riferibili a una coppia di coordinate, pertanto rinomineremo i campi “Lat” e “Lon” del CSV nei prosaici “Latitude” e “Longitude” mediante il modulo “Rename”.
 Lo standard GeoRSS prevede alcuni item che consentono di arricchire di informazioni descrittive ogni elemento geotaggato, poi visibili nel “balloon” ad esso associato in fase di visualizzazione su mappa.
Lo standard GeoRSS prevede alcuni item che consentono di arricchire di informazioni descrittive ogni elemento geotaggato, poi visibili nel “balloon” ad esso associato in fase di visualizzazione su mappa.
Naturalmente si tratta di informazioni residenti nel CSV, che noi andremo opportunamente a rinominare in modo da consentire a Pipes di includerle nel singolo elemento del GeoRSS. Si tratta essenzialmente di:
- <title> – il titolo dell’elemento, in questo caso il distretto sismico nel quale è avvenuto l’evento;
- <link> – l’URL alla risorsa associata all’elemento, ovvero la pagina dedicata al singolo evento sismico, realizzata dall’INGV;
- <description> – la descrizione dell’elemento, con la magnitudine, la profondità dell’ipocentro e la data del terremoto.
Passeremo queste informazioni al Pipe semplicemente usando sempre il modulo “Rename” avendo stavolta l’accortezza di scegliere l’opzione “Copy As”.
 Qui sopra per <title>, con la necessità di sostituire l’antiestetico underscore presente nel campo “Locality” del CSV con uno spazio vuoto (blank) grazie al modulo “Regex”.
Qui sopra per <title>, con la necessità di sostituire l’antiestetico underscore presente nel campo “Locality” del CSV con uno spazio vuoto (blank) grazie al modulo “Regex”.
La <description> dell’elemento geotaggato come già detto è costituita da magnitudine, profondità dell’ipocentro e data dell’evento sismico, informazioni presenti in tre differenti campi del CSV, che andremo a comporre in un’unica stringa grazie al modulo “String Builder”. Questo verrà utilizzato però nell’ambito di un modulo “Loop”, poichè è un’operazione che va ripetuta per ogni elemento presente nel CSV.

Notate come il risultato dello String Builder vada ad essere assegnato all’item <description>.
L’INGV, per ogni evento sismico registrato, genera una pagina html che riporta informazioni estremamente dettagliate riguardanti il terremoto, molto preziose per chi si occupa di sismologia, di protezione civile o comunque davvero interessanti anche a scopo didattico. Qui quella relativa al famigerato evento del 6 aprile scorso che ha devastato l’Aquilano.
Osservando l’URL si nota che la stringa risulta la seguente:
http://cnt.rm.ingv.it/data_id/[codice evento]/event.html
dunque ciò che cambia è il codice evento, registrato nel campo “Code” del CSV. Ancora una volta, useremo la combinazione dei moduli “Loop” e “String Builder” per costruire il link alla pagina di ogni evento, assegnando il risultato all’item “eventoURL” che verrà poi rinominato nell’item <link>.
 Dulcis in fundo… il modulo che genera il vero e proprio GeoRSS… voilà, si tratta di “Location Extractor”.
Dulcis in fundo… il modulo che genera il vero e proprio GeoRSS… voilà, si tratta di “Location Extractor”.
 Voi direte: “embè, e i parametri dove sono?!?”. E’ quel che mi son chiesto anch’io quando l’ho visto. Ma poi leggendo la descrizione del modulo (cosa che vi consiglio vivamente di fare), si capisce come funziona:
Voi direte: “embè, e i parametri dove sono?!?”. E’ quel che mi son chiesto anch’io quando l’ho visto. Ma poi leggendo la descrizione del modulo (cosa che vi consiglio vivamente di fare), si capisce come funziona:
Questo modulo esamina il feed in input, alla ricerca di informazioni che indichino una località geografica. Se trova dati geografici, il modulo crea una y:location che costituisce l’elemento di output. Questo contiene svariati sotto-elementi, in funzione del feed di input.
Dunque fa tutto lui. In pasto possiamo dargli sorgenti GML, W3C Basic Geo, tags KML e ovviamente GeoRSS, in output fornirà appunto l’elemento y:location, che potrà essere visualizzato direttamente su una mappa interattiva Yahoo Map. Qui sotto il risultato…
Ma il vero valore aggiunto del pipe è quello di poter essere impiegato in svariati modi, dal “banale” embedding della mappa in blog e siti web, per finire ad altri davvero potentissimi, riutilizzabili in una miriade di modalità. Solo per citarne alcuni JSON, PHP, KML e ovviamente GeoRSS.

E proprio il GeoRSS può essere usato ad esempio con OpenLayers, scrivendo un pò di codice html è possibile in pochi minuti importare il feed generato dal pipe come layer grazie alla call OpenLayers.Layer.GeoRSS ottenendo una mappa semplice ma efficace, come si vede in questo esempio… Altre modalità di fruizione del GeoRSS – generate sempre in modo automatico – le riporto qui appresso giusto per coloro che non hanno voglia di andare a consultare la pagina del pipe:
Insomma, a noi Yahoo Pipes ci fa letteralmente sognare… Perchè sapere di avere uno strumento col quale poter attingere, trasformare, plasmare e “ricablare il web” (il loro slogan) e i dati sparsi per il mondo usando la logica ad oggetti, dedicando i propri neuroni solo ed esclusivamente alle idee e al modo di tradurle in fatti… beh, è davvero troppo, troppo entusiasmante.
E allora “Yes, we Pipe!”… ma prima ancora “Linked Data… now!!!”.
Posted in Didattica | 4 Comments »
19 maggio, 2009 | di Andrea Borruso
Grazie ad una discussione su GFOSS, e grazie a Stefano Costa e a Mando, ho avuto diverse informazioni su un workshop a cui sarei andato con molto piacere: il IV workshop nazionale su “Open Source, Free Software e Open Format nei processi di ricerca archeologica”. Si è parlato anche di applicazioni spaziali.
Vi consiglio di iniziare dal report che ha scritto Stefano, di cui mi piace sottolineare queste frasi:
[... ]Tuttavia, non possiamo pensare di evolvere in una nuova archeologia senza impegnarci in primis per una buona archeologia. La buona teoria e il buon metodo sono tali se si traducono e dialogano con una buona pratica della ricerca (intesa non solo come ricerca sul campo, ma in senso lato di processo operativo e conoscitivo) e viceversa.[... ]
La cosa bella, per chi come me non era presente, è che gli interventi del congresso sono stati pubblicati in streaming (dal CNR) . Queste le tematiche principali:
- Patrimonio Culturale – OPEN PROCESS
- Patrimonio Culturale – OPEN DATA
- Patrimonio Culturale – OPEN SOFTWARE
- Patrimonio Culturale – OPENLAB
- Patrimonio Culturale – OPEN LEARNING
Io mi sono già guardato GRASS E OSGEO: un framework per l’archeologia, ma non mi fermerò qui e consiglio a tutti di fare la stessa cosa.
Buona visione.
Posted in Eventi | No Comments »
24 ottobre, 2008 | di Pietro Blu Giandonato
Non so quanti di voi abbiano seguito i lavori della O’Reilly Where 2.0 Conference di quest’anno, anche solo virtualmente attraverso i video delle presentazioni. Andrea ne aveva già richiamato l’attenzione in un suo precedente post. Chiunque abbia avuto la fortuna di essere là, avrà respirato aria frizzante, e magari si sara’ chiesto come mai tra i relatori ci fossero figure professionali mosse da filosofie e intenti tanto diverse: società private, ricercatori e professionisti del GeoWeb. Cosa mai si saranno detti? Perché uno sviluppatore di software open-source avrebbe dovuto accettare di parlare dopo un esponente di ESRI o Google? A giudicare dalle presentazioni che mi è capitato di vedere in video streaming, sono domande fuori luogo.
Ciò che mi ha colpito profondamente è invece la grande visionarietà degli interventi. Ognuno di loro era lì per raccontare il proprio sogno, nella convinzione che l’idea della quale avrebbe parlato, avrebbe portato una rivoluzione. Detta così sembra una boutade. E invece no. Si tratta di gente che sa quel che dice.
Di recente A. Turner e B. Forrest hanno scritto Where 2.0: The State of the Geospatial Web, un report che tenta di tirare le somme di quelle giornate. Impresa davvero titanica, e loro ne sono consapevoli. E per questo hanno voluto concentrare la loro attenzione su alcuni concetti chiave venuti fuori dai lavori della conferenza. Il documento è costituito da due parti, nella prima c’è la ciccia, mentre la seconda è una sorta di Pagine Gialle, con un profilo delle aziende e dei soggetti operanti nel settore. I due autori hanno messo a disposizione solo un estratto, le prime 15 pagine, sufficienti comunque a farsi un’idea di quali siano i trend che di qui a qualche anno diverranno il fulcro di tutta la partita che si giocherà attorno al GeoWeb. Io personalmente ho letto solo l’estratto, perchè francamente non mi andava proprio di spendere $400 per acquistare le restanti 40 pagine del report. Comunque, mi piacerebbe discutere di questi trend proprio qui, sia “saccheggiando” che commentando il documento, nella convinzione che siano di interesse per chi cerca di vivere delle cose che ci piacciono TANTO.
Innanzitutto, è importante soffermarsi su un nuovo paradigma sul quale poggiano queste riflessioni, ovvero proprio “Where 2.0“. Alla O’Reilly si riferiscono con questo termine all’emergente Geospatial Web, con un palese riferimento al Web 2.0: internet come piattaforma anche per le applicazioni geografiche. Nel Web 2.0 i dati sono diventati servizi, non più il software. Servizi che letteralmente diventano migliori quanto piu’ vengono utilizzati.
Il futuro sistema operativo, basato su internet, dovrà essere dotato di sottosistemi capaci di attingere a numerose e svariate fonti di dati, e di mescolarle. Questi dati saranno con il tempo quelli piu’ aggiornati, sia da soggetti commerciali che dalle community di volontari e appassionati. Tra questi sottosistemi, il GeoWeb è forse quello maggiormente sviluppato, perché è “multiplayer” e “multilayer”; un melange ricco di dati, servizi e opportunità. Uno dei concetti chiave che è possibile imparare dal GeoWeb, è come i suoi sottosistemi di dati si propongano come mercati aperti quando esiste un substrato, solido e standardizzato, sul quale altri dati possano essere sovrapposti.
Ad esempio il fenomeno dei mashup si è diffuso da quando è stato “hackerato” il sistema di implementazione dei dati di Google Maps. Big G, lungimirante, ha poi immediatamente rilasciato le proprie API aperte (a proposito, qualcuno di voi ha ricevuto la stizzita email del PCN sul “saccheggio” delle ortofoto?). Da quel momento le innumerevoli applicazioni basate su quelle API proliferano in maniera vertiginosa giorno dopo giorno.
E allora? E allora il GeoWeb non può fare a meno di soggetti – privati, pubblici e “open” – capaci di fornire software, dati e IT – ma soprattutto idee e progetti – che per la natura intrinseca del GeoWeb, hanno grandi potenzialità di integrazione tra essi. La sfida per tutti noi che siamo in ballo è dunque quella di trovare la propria dimensione, la propria vocazione nella grande entropia del GeoWeb: sarà la capacità di leggere i trend verso i quali questo complesso universo si muove, che ci permetterà di lavorare al meglio, senza mai sentirsi indietro anni luce rispetto agli altri. La Geografia sarà sempre libera.
Qui di seguito vengono brevemente riportati proprio i trend più interessanti per il GeoWeb – presenti nel report – intesi soprattutto come opportunità per chi opera a vario titolo nel settore. Appare immediata l’enorme dinamicità di alcuni progetti già maturi, come pure le grandi potenzialità di altri ancora in embrione. Colpisce davvero molto proprio questa grande entropia che caratterizza il GeoWeb e tutto ciò che gli ruota intorno.
Merging data colllection with data maintenance.
Nokia ha acquisito la Navteq e TomTom la Tele Atlas; ciò fa capire come i geodati di base – in questo caso i grafi stradali – siano una risorsa fondamentale per applicazioni di geolocation e PND. I costi di manutenzione e aggiornamento di tali dati sono però elevatissimi. E allora sono state messe a punto tecnologie di aggiornamento di tipo attivo e passivo, entrambe coinvolgono gli stessi utilizzatori dei sistemi. TomTom, con MapShare consente agli utenti di segnalare errori nella viabilità, mentre Dash Navigation monitora continuamente i viaggi degli utenti – alla faccia della privacy! – in tal modo statisticamente puo’ individuare i cambiamenti nella viabilità e gli errori nei dati.
Open Data
Il valore propositivo dei dati aperti è il medesimo del software open source: individui e società commerciali contribuiscono al mantenimento del grosso dei dati, cosicché tutti possano beneficiarne. I dati vengono forniti in formati aperti e licenze non proprietarie. Uno dei migliori esempi di progetto che si basa sulla disponibilità di dati aperti e pubblici è GeoNames, che ha costruito un database con i nomi delle località provenienti da fonti di dati pubbliche. Purtroppo l’appetito vien mangiando, e GeoNames sta progressivamente riducendo l’accesso gratuito ai propri servizi, richiestissimi, comunque ampiamente sufficienti alle esigenze dei più.
User generated geospatial information.
Analogamente all’aggiornamento e manutenzione dei dati esistenti di cui s’è parlato prima, gli utilizzatori del GeoWeb possono diventare creatori di nuovi geodati sia in modo passivo che attivo. Al primo caso possiamo ascrivere il servizio di geotagging di foto e video di Flickr. Gli utenti, geoposizionando le proprie foto, e vi associano anche dei tag che quasi sempre sono almeno il nome del luogo. In questo modo si viene a creare un grande database di nomi di luoghi (toponimi?) che puo’ avere un dettaglio anche maggiore dei prodotti “ufficiali”. Un esempio invece di creazione di geodati totalmente nuovi in maniera aperta e comunitaria è il maiuscolo OpenStreetMap. Una sintesi fantastica delle due cose è questa: un’interfaccia di webmapping con alcune foto di Flickr scattate a Pechino, e OpenStreetMap come base cartografica. L’esempio ci fa capire come sia facile mescolare fonti e tecnologie, ma soprattutto quanto siano efficaci progetti aperti di questo tipo (qui per saperne di più). Un progetto molto simile, che integra basi di conoscenze differenti (logs GPS, foto geotaggate) – certamente conosciuto dagli escursionisti non “tecnolesi” – è EveryTrail, grazie al quale è possibile scaricare percorsi trekking con tanto di foto. Ovviamente si tratta di un progetto alimentato in maniera volontaria, su formati di dati aperti (stavolta GPX).
Open*.org
Ma OpenStreetMap è anche di più. Il progetto si è ormai espanso, oltre che come quantità e qualità dei dati anche come tipologia, ed ora oltre a quelli stradali si possono trovare anche dati sull’uso del suolo e addirittura imagery raster, grazie al progetto parallelo OpenAerialMap. Progetti di questo tipo, alimentati in maniera volontaria, basati su OS e con dati non coperti da copyright, hanno fatto comprendere ad alcuni soggetti privati del settore che possono essere una risorsa, anzichè concorrenti. La Automotive Navigation Data, società olandese di PND, ha infatti donato gratuitamente a OSM la propria copertura di dati per l’Olanda e la Cina, la contropartita è ovviamente quella di utilizzare i dai OSM da parte di AND. Innegabili sono infatti le potenzialità di dati liberi generati da comunità di utenti, contro quelli proprietari generati da società private. Un esempio ne è la copertura stradale di Khartoum del progetto OSM (qui) contro quella di Google Maps, con dati NAVTEQ (qui).
L’importanza di essere aperto
Ed è cambiato anche il paradigma legato ai dati con formati aperti e liberi di essere usati. Sebbene qui in Italia sia ancora controversa e difficile la situazione su libero utilizzo e libera distribuzione dei dati detenuti da soggetti pubblici (enti locali, università, ecc), a livello globale l’emergere e affermarsi di standard come KML e GeoRSS obbliga di fatto tutti i soggetti coinvolti a vario titolo nel GeoWeb a concentrarsi ancora una volta sulla ricchezza dei dati e l’architettura dei servizi, piuttosto che sulle scelte tecnologiche e di sviluppo delle applicazioni per poterli usare. Il risultato che ne deriva è una base di conoscenze costruita in maniera condivisa e spontanea, costituita da informazioni non strettamente spaziali, ma che possiedono un valore geografico. Ecco che le foto di Flickr ormai da tempo possono essere geotaggate, come pure i video di Youtube, ed ovviamente essere esportati in KML per venire utilizzati in qualunque applicazione. Un paio di settori in forte espansione sono infatti quello relativo alla conversione di dati da formati proprietari ad aperti – che per le grandi organizzazioni non è uno scherzo affrontare – e il geotagging di documenti e contenuti di qualunque genere, per renderli pronti ad essere utilizzabili nel grande mondo del GeoWeb, in continua, incessante ed inesorabile espansione.
Concludo queste considerazioni sul GeoWeb – fortemente ispirate dal report O’Reilly – ringraziando Andrea, sempre prodigo di consigli e suggerimenti, che mi ha segnalato una delle sue prodigiose scoperte: la presentazione Beyond Google Maps che Mapufacture/Geocommons hanno tenuto al Future of Web Applications FOWA 2008 a Londra. Riesce a sintetizzare con poche parole e molte immagini i concetti dei quali abbiamo discusso qui, dipingendo un futuro davvero entusiasmante per il GeoWeb. Futuro che – in realtà – è già presente…
Godetevela qua sotto, e naturalmente date un’occhiata al report di O’Reilly.
Ultim’ora: Andrea mi segnala che stasera 24 ottobre, alle 18:00 ora italiana, Andrew Turner terrà il webcast “Trends and Technologies in Where 2.0″, assolutamente da non perdere, iscrivetevi, ci vediamo là!
Posted in Dati | 1 Comment »
17 luglio, 2008 | di Pietro Blu Giandonato
La grande ambizione del progetto OneGeology.org è quella di creare e mettere a disposizione di tutti la grande carta geologica digitale del mondo intero…
Si tratta di un’iniziativa internazionale, promossa dalla rete dei Servizi Geologici di numerosi Paesi, dalle Americhe all’Europa, dall’Africa fino all’Asia. L’Italia è rappresentata dall’Agenzia per i Servizi Tecnici Nazionali (APAT), che anni fa ha fagocitato il glorioso e compianto Servizio Geologico d’Italia.
Ah, giusto per completezza, pare che il nuovo Governo voglia diluire ulteriormente il ruolo dell’APAT accorpandola con l’ICRAM e INFS, per costituire l’Istituto di Ricerca per la Protezione Ambientale (IRPA)… a voi le riflessioni.
Gli obiettivi di OneGeology sono essenzialmente:
- Rendere accessibili le carte geologiche esistenti in qualsiasi formato digitale siano disponibili in ogni Paese.
- Trasferimento di know-how a coloro che ne hanno bisogno, adottando un approccio che riconosca che le diverse nazioni hanno differenti capacità di partecipazione.
- Stimolare un rapido aumento dell’interoperabilità, attraverso lo sviluppo e l’uso del “GeoSciML”, un Geography Markup Language per le geoscienze. Per saperne di più fare clic qui.
Le carte geologiche fornite dai Paesi partecipanti possono essere ammirate grazie al geoportale del progetto, mediante una semplice applicazione webgis che riesce a mosaicare i dataset geologici. E’ possibile esportare le mappe costruite nel geoportale in KML o WMC per poterle ammirare in Google Earth o in altre applicazioni che supportano questi formati.
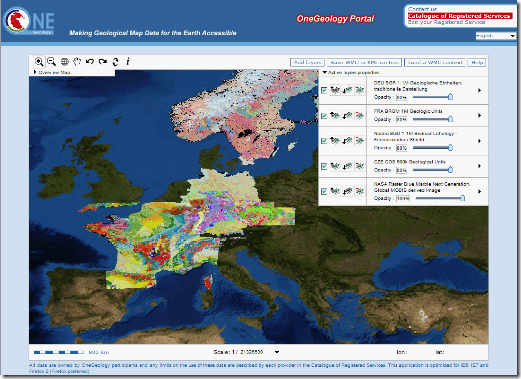
Insomma… una iniziativa davvero interessante e lungimirante, soprattutto nell’ottica di rendere accessibili in maniera semplice ed aperta dati che altrimenti rimarrebbero disponibili solo ad una stretta cerchia di addetti ai lavori.
Dimenticavo… vi consiglio vivamente di visitare ora e in futuro, perchè in continuo aggiornamento, la sezione OneGeology eXtra con curiosi riferimenti all’influenza che la Geologia ha avuto in numerosi altri campi dello scibile umano (Culture), risorse fantastiche per la didattica (OneGeology4Youngsters) e uno Showcase con i migliori esempi di utilizzo della cartografia geologica digitale…
Up the Geology!!
Posted in News | 4 Comments »















