






Introduzione
Il GTFS è un formato nato per definire orari e informazioni geografiche legate a reti pubbliche e private di trasporto. E’ nato in sintesi estrema (qui più dettagli) come side project di un dipendente di Google che nel 2005 stava cercando un modo per standardizzare l’importazione di dati di questo tipo in Google Maps. Non c’era ancora uno standard in questo settore, e nel tempo il GTFS è diventato il formato di riferimento, grazie anche all’uso diffuso e alla sua documentazione.
Si tratta di una collezione di file CSV (con estensione .txt) – da un minimo di 6 a un massimo di 13 – archiviati all’interno di un file zip, le cui specifiche sono documentate qui: https://developers.google.com/transit/gtfs/reference/
Per varie ragioni è un formato con cui ho spesso a che fare, ed è stato di ispirazione per creare uno script che ho scritto durante le bellissime olimpiadi di Rio e che ho chiamato GTFS, ready, set, go.
Cosa è GTFS, ready, set, go
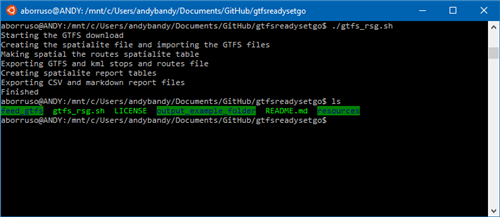
È uno script bash che fa essenzialmente una cosa: trasforma i file txt del GTFS in formati pronti per essere usati meglio e subito, sopratutto in applicazioni spaziali. Nel dettaglio:
- scarica una sorgente dati GTFS e ne converte i file
txtin tabelle di un DBMS con estensione spaziale e in particolare in formato spatialite (evviva Alessandro Furieri e tutti quelli che si prendono cura di spatialite);- trasforma in layer cartografici le tabelle delle fermate e delle rotte (
stopseroutes); - genera alcuna tabelle utili a creare un report sul file della reti di trasporti preso in esame;
- trasforma in layer cartografici le tabelle delle fermate e delle rotte (
- esporta in formato
GeoJSONeKMLla tabella delle rotte e quella delle fermate; - genera un report in formato
HTMLeMarkdownutili a dare una visione d’insieme dei dati in esame (al momento è ancora minimale e in bozza) .
Nulla di complesso e nulla di nuovo. Ci sono già altre modalità e prodotti per fare cose simili, ma sono scritti in linguaggi che non conosco (ad esempio in Go), richiedono l’installazione di un database server o non spazializzano database sqlite (come il mio amato GTFSDB) o sono procedure (semplici) da svolgere “a mano” e quindi a rischio sempre di qualche errore e con perdite di tempo (come ad esempio questa).
Qui il repository su GitHub: https://github.com/ondata/gtfsreadysetgo
Come funziona
Si tratta di uno script in cui ho messo in fila i comandi utili al mio obiettivo finale, costruendo una (sorta di) macro in cui sfrutto le caratteristiche del bash e alcune utility/applicazioni utili per arrivare al risultato atteso. Queste ultime sono al momento un requisito per lo script, e quindi una piccola barriera ad un utilizzo immediato: le ho utilizzate perché mi hanno consentito di non scrivere “vero” codice, perché “fanno” nella sostanza tutto loro.
Requisiti
Avere un sistema operativo in cui è possibile lanciare uno script bash, quindi ovviamente i sistemi Linux, quelli Mac e anche quelli Windows. Su quest’ultimo apro una piccola parentesi.
Per lanciare uno script bash su Windows – sino a poco tempo fa – era necessario installare “cose” come Cygwin.
Cygwin è una distribuzione di software libero, sviluppata originariamente da Cygnus Solutions, che consente a diverse versioni di Microsoft Windows di svolgere alcuni compiti in maniera esteticamente e funzionalmente simile ad un sistema Unix (da Wikipedia).
Dall’ultimo aggiornamento di release di Windows 10 (l’anniversary update di agosto 2016) è possibile utilizzare nativamente bash anche in Windows, tramite l’applicazione denominata “Bash in Ubuntu on Windows”; “GTFS ready set go” l’ho scritto e testato per intero in ambiente Windows 10, anche per provare questa novità introdotta in questo recente aggiornamento, che rende la comodità e la potenza di fuoco di bash sempre più trasversali.
Lo script sfrutta queste applicazioni:
- GDAL – Geospatial Data Abstraction Library >= 2.1, che viene usato essenzialmente per le operazioni di creazione, importazione e esportazione delle risorse;
- spatialite, che viene sfruttato per fare query spaziali e come uno dei formati di archiviazione e output;
- unzip, per decomprimere il GTFS sorgente;
- curl, per il download del file GTFS;
- csvtk, per convertire in formato Markdown alcune delle tabelle create;
- pandoc, per convertire il report Markdown anche in formato HTML.
E infine vengono utilizzate gli straordinari grep e sed, che sono sempre presenti in ambienti in cui è possibile lanciare uno script bash.
Usare lo script
Questa la modalità attuale di utilizzo:
- scaricare (o clonare) il repository e decomprimere in una cartella il file zip scaricato;
- dare allo script
.shi permessi di esecuzione; - aprirlo con un editor di testo e cercare la variabile
URLGTFS; - sostituire l’URL presente con l’URL di un feed GTFS di proprio interesse (un comodo archivio di GTFS è TransitFeeds) come ad esempio quello di Madrid https://servicios.emtmadrid.es:8443/gtfs/transitemt.zip;
- salvare e lanciare lo script via shell.
Qui sotto la replica di quanto descritto nei punti di sopra.
Alcune note
Lo script può essere migliorato e di molto. Per questa ragione inserisco alcune importanti note:
- lo script non fa la verifica dei requisiti software (vedi sopra), quindi se non soddisfatti andrà in errore;
- lo script è utilizzabile al momento soltanto con i GTFS che contengono anche la tabella
shapes, che è opzionale per il formato GTFS, quindi non sempre presente; - lo script non fa alcuna verifica di consistenza dei dati (per la quale è possibile utilizzare FeedValidator;
- lo script crea e cancella file e cartelle nella cartella in cui viene eseguito.
Gli output
Sopra ho già fatto riferimento agli output. Nel repository oltre allo script è stata creata la cartella output_example_folder per mostrare nel concreto quali siano gli output prodotti. A seguire l’elenco dei vari output con i relativi URL, in modo da potersi fare un’idea più concreta:
feed_gtfs.sqlitedownload, ovvero il file GTFS trasformato in formato SpatiaLite, in cui le tabellestopseroutessono state trasformate in layer spaziali;routes.geojson(visualizzazione e download), il file in formato GeoJSON per le rotte;routes.kml(download), file in formato KML per le rotte, visualizzabile in Google Earth (ed in altri client);stops.geojson(visualizzazione e download), il file in formato GeoJSON per le fermate;stops.kml(download), file in formato KML per le fermate, visualizzabile in Google Earth (ed in altri client);- la cartella
report(visualizza), che a sua volta contiene:report.md, il file con il report in formato Markdown (visualizza)report.html, il file con il report in formato HTML (vista codice e rendering HTML);- tutte le tabelle usate per costruire i report, in formato CSV e Markdown.
Perché
GTFS, ready, set, go nasce come conseguenza di #openamat, un’iniziativa civica (ancora in corso) per chiedere a AMAT (la municipalizzata comunale di Palermo che gestisce il trasporto pubblico) di pubblicare i dati relativi ai trasporti pubblici in formato aperto ed in tempo reale.
Dopo 6 mesi senza aggiornare i dati, AMAT ha pubblicato a luglio del 2016 tre aggiornamenti di GTFS in 15 giorni e avevo bisogno di uno script per poter usare e visualizzare subito questi dati.
Lo rendo pubblico perché penso possa essere utile anche ad altri.


