Da settimane vedevo rimbalzare su Facebook condivisioni di post a dir poco preoccupanti, che dipingevano una costa abruzzese dalle acque putride, in cui anche solo pensare di fare il bagno sarebbe stato masochismo puro, quasi un tentativo di suicidio! Foto di topi morti in spiaggia, di fiumane marroni, cariche di non meglio specificati “fanghi tossici” e i racconti dell’amico del cugino di un amico, a cui erano spuntate le più strane eruzioni cutanee dopo aver messo un piede in acqua, si susseguivano senza sosta. Dopo un po’ stavo iniziando a notare che questi argomenti, man mano che si stava entrando nel vivo della stagione estiva, stavano migrando dal mondo virtuale dei social a quello reale, e facevano sempre più spesso capolino nei discorsi di amici e conoscenti.
Personalmente, ho sempre fatto il bagno nel mare davanti casa e, pur riconoscendo che non si tratta di un mare dalle acque cristalline, come quello che si vede nelle classiche foto che ritraggono le località turistiche della Sicilia o della Sardegna (sfido io, si parla di un tratto di costa del medio Adriatico, di natura principalmente sabbiosa!), devo dire che non ho mai contratto strane malattie riconducibili al contatto con l’acqua di mare, né sono andato a sbattere contro carogne decomposte di animali mentre nuotavo. Al massimo mi sono beccato qualche puntura da meduse e tracine, che erano sicuramente vive e vegete… e decisamente reali!
Possibile che la situazione, di colpo, sia precipitata a tal punto? Non sarà, forse, che si viene in contatto con delle “notizie” da fonti non proprio autorevoli, si sbircia superficialmente qualche fake che spunta sui social e a furia di sentir parlare di certe cose se ne dà per certa la veridicità un po’ troppo facilmente?
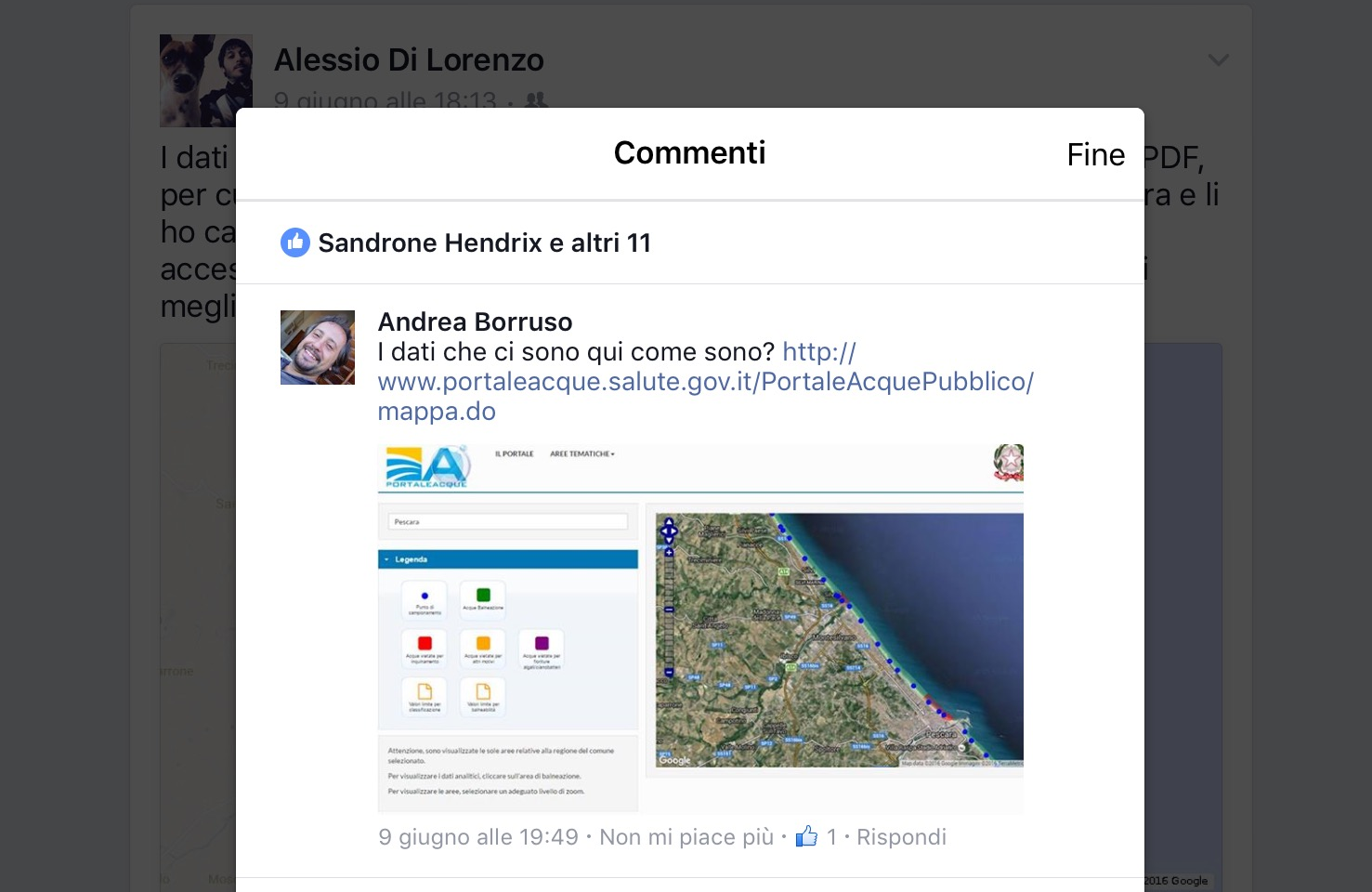
Così ho fatto la cosa teoricamente più ovvia del mondo: una ricerca su Google. In non più di 10 minuti ho rinvenuto, sul sito dell’Agenzia Regionale per la Tutela dell’Ambiente (ARTA), le informazioni che volevo. Tutto era riportato negli allegati della D.G.R. 148 del 10/03/2016 e in un’applicazione web della stessa ARTA, da cui era possibile scaricare i risultati delle analisi in formato Excel e PDF.
Entusiasta di questa scoperta ho subito pensato di realizzare un’applicazione di web mapping, di quelle che “mi piacciono TANTO”, per facilitare la lettura dei dati messi a disposizione dall’ARTA. Il mio entusiasmo, però, si è smorzato non poco quando ho notato che l’unico file in cui erano riportate le coordinate dei limiti dei tratti di costa analizzati e dei punti di prelievo era il PDF della D.G.R.
Storcendo un po’ il naso, l’ho scaricato, ho estratto le pagine con i dati e, dopo un paio di tentativi poco fortunati di tirarne fuori in maniera (semi)automatica qualcosa di utilizzabile con dei programmi OCR online, mi sono rassegnato a ricopiare a mano le righe che riguardavano la mia provincia (Pescara) in un file di testo che ho poi salvato in CSV. Usando questo file parziale ho creato una mappa tematica semplicissima con Google My Maps e l’ho condivisa, molto poco soddisfatto del risultato, su Facebook, dicendomi: “Meglio di niente!”. Nonostante non fossi soddisfatto a livello tecnico, l’obiettivo si poteva dire raggiunto: i risultati delle analisi dicono che l’acqua è sostanzialmente pulita, addirittura di qualità eccellente lungo gran parte della costa. Alla faccia del disfattismo e del qualunquismo da tastiera.
Discorso chiuso? Sembrava di sì, anche perché nel frattempo avevo scritto una mail all’ARTA chiedendo gli stessi dati del PDF, ma in un formato diverso, senza ricevere alcuna risposta. Come al solito, però, Andrea è stato in grado di darmi un suggerimento fondamentale:
Grazie ai dati del Portale Acque, distribuiti sotto licenza CC per mezzo di una serie di servizi ReST (per quanto non sia ancora riuscito a capire fino in fondo come sono strutturati) la musica è cambiata radicalmente e, realizzando uno script in PHP per il recupero dei dati in cross origin e un client Javascript basato sull’ottimo Bootleaf, ho sviluppato una sorta di clone dell’applicazione di web mapping ufficiale, con la differenza che la mia considera i soli dati sulla costa abruzzese e che la tematizzazione della mappa non si limita a classificare le zone indagate secondo una scala di due colori (verde/rosso = aperto/chiuso) ma riprende una scala più fine che, sul Portale Acque, è espressa da un simbolo colorato visibile solo accedendo con un clic al pannello di dettaglio di ogni zona. La potete vedere all’opera cliccando qui, mentre qui trovate il repository con il codice su GitHub.
A lavoro ultimato ho pubblicato un nuovo post sui canali social e stavolta, non so se per il maggior “impatto estetico” della nuova applicazione o per la più immediata leggibilità rispetto al tentativo precedente, in poche ore ho ottenuto diversi commenti con richieste di dettagli, svariate condivisioni e sono stato anche contattato telefonicamente da una persona che mi voleva far intervistare da una sua collaboratrice per un quotidiano locale.
Insomma, mi posso ritenere soddisfatto del risultato perché probabilmente, oggi, c’è in giro qualche persona in più che, anche grazie alla mia piccola opera di divulgazione e a un po’ di sano passaparola (perché basato su dati oggettivi), sa che può andare al mare in Abruzzo e fare il bagno avendo delle buone probabilità di portare a casa la pelle.
In chiusura, mi preme sottolineare quanto sia importante rendere accessibili e divulgare nel modo più chiaro possibile dati di interesse pubblico come questi, evitando di dare respiro alle chiacchiere, al disfattismo e ai facili allarmismi, che al giorno d’oggi corrono veloci sulla rete, attecchiscono più facilmente e sono più duri da sradicare dell’erba cattiva!
Gli eventi abruzzesi mi hanno toccato molto. Non poteva essere diversamente.
Sono un geologo e mi occupo di sistemi informativi geografici; posso dare un piccolo aiuto anche io, sfruttando le mie attitudini e le mie competenze?
Per giorni non ho trovato la risposta, poi mi contatta in chat Alessio Di Lorenzo, un amico biologo abruzzese e curatore del portale cartografico del Parco Nazionale della Majella, e mi chiede se conosco una fonte da cui estrapolare dei dati sugli eventi sismici di questi giorni. Li vuole elaborare e trasformare in una sorgente geoRSS, prendendo spunto proprio da quanto abbiamo scritto qui. Inizialmente la cosa mi ha fatto piacere, ma non mi ha stimolato nulla. In seguito, aprendo l’URL che gli ho inviato, quello del Centro Nazionale Terremoti dell’Istituto Nazionale di Geofisica e Vulcanologia, qualcosa mi ha fatto “click” in testa. Ma “poco poco, piano piano”.
Mi sono passati davanti agli occhi, i dati sismici pubblicati in questi giorni. Quelli “ufficiali”, quelli presentati dai giornali online di tutto il mondo, quelli sui blog. Alcuni sono caratterizzati da piccole grandi carenze, potenzialmente superabili con poco sforzo, ma con origini che sono profonde.
Tim Berners-Lee, uno degli “inventori” del World Wide Web, ha presentato nello scorso Febbraio una relazione orale sul futuro del Web (grazie a Stefano Costa per la segnalazione). E’ visibile in diversi siti, e gli dovreste dedicare 15 minuti del vostro tempo (se la guardate qui ci sono i sottotitoli, ha un inglese “difficile”), qualsiasi mestiere facciate. In quella sede ha lanciato uno slogan: “raw data now“, letteralmente “dati grezzi ora”. Ha invitato il “mondo”, gli enti pubblici e quelli privati, a “liberare” i propri dati e creare i presupposti affinché questi possano essere accessibili e mescolati tra loro. Ha invitato inoltre tutti noi a stimolare chi detiene dati, a muoversi in questo senso; senza la condivisione, questi perdono quasi del tutto la loro qualità.
Berners-Lee individua tre regole:
deve bastare un semplice indirizzo web, un URL, per puntare ad un dato
chiunque abbia accesso a quell’URL, deve poter scaricare i dati in qualche formato standard
devono essere descritte le relazioni tra i dati (Andrea è nato a Palermo, Palermo è in Italia, etc.), e queste relazioni devono essere espresse ancora una volta tramite un’URL
Questo sarà il web 3.0, basato sui dati e (si spera) sulle relazioni semantiche tra gli stessi. Ma torniamo ai dati sismici sul nostro paese. Rispettano queste tre regole?
Questa non sarà una critica al CNR ed all’INGV. Leggo sul loro sito, che gran parte dei dati da loro pubblicati in questo contesto, sono affidati (ancora una volta) al volontariato. A molti dipendenti infatti sembra non sia stato rinnovato il contratto. Non conosco questa situazione, ma è molto triste anche soltanto immaginare che una funzione di questo tipo possa essere “relegata” a semplici attività di volontariato.
Quello dei dati sismici è per me solo uno spunto, ed il discorso va allargato a tutti i contesti in cui esistano dei dati pubblicati in modalità poco efficienti (o addirittura non pubblicati).
Il formato in cui sono accessibili gran parte dei dati sismici è il CSV :
è un formato di file basato su file di testo utilizzato per l’importazione ed esportazione (ad esempio da fogli elettronici o database) di una tabella di dati. Non esiste uno standard formale che lo definisca, ma solo alcune prassi più o meno consolidate.
Un esempio pratico è quello delle date, espresso in alcuni file dell’INGV in questo formato YYYY/MM/DD (2009/04/13). Aprendo uno di questi file con un foglio elettronico, il campo “data” verrà quasi sicuramente interpretato in automatico ed adattato alle impostazioni “locali” del vostro PC. Su molti PC italiani, sarà infatti forzato questo formato: DD/MM/YYYY (13/04/2009). E’ la stessa data? Sembra di si. Ma se iniziassimo a scambiare questi dati con colleghi, che usano un semplice blocco note per aprire il file CSV (senza quindi che i dati siano “trasformati”), o che vivono in un altro paese (quindi con un’impostazione locale differente), in quanto tempo ne perderemmo l’integrità?
Usando degli standard, ad esempio per le date l’ISO 8601 , riusciremo a dare ai nostri dati una vita più lunga ed anche una “platea” molto più estesa.
Altre volte i dati sono pubblicati come tabelle HTML. Avete mai provato a fare copia ed incolla di una tabella, da una pagina web ad un foglio elettronico? Molte volte se ne esce con le ossa rotte.
E’ giusto pubblicare i dati in html, ma dovremmo sempre fornire anche altre possibilità. Il servizio geologico americano (“so forti li americani”), lo USGS, pubblica da tanti anni un catalogo di eventi sismici in tre formati: KML (il formato di Google Earth che è ormai uno standard OGC), CSV ed XML (geoRSS). E’ una scelta che mi sembra cristallina. Si conciliano infatti formati adatti ad un’immediata divulgazione, con un formato RAW (come direbbe Tim Berners-Lee). Il file KML e quello XML consentono ai dati di essere interpretati correttamente da una macchina e di essere “mescolati” più facilmente con altri provenienti da altri pc, scritti con altri software e prodotti da altri gruppi di lavoro. Questa opportunità è un aspetto molto importante, in quanto l’incrocio di dati diversi spesso fa saltare agli occhi significati inaspettati; a costo di essere noioso, se non definisco i miei dati in un formato standard, sarà difficile riuscire a correlarli “immediatamente” con altri. L’INGV si sta muovendo sullo stesso solco, e in questa pagina troverete i dati degli eventi sismici degli ultimi 90 giorni sia informato CSV, che KML. Ma troverete anche questo avviso:
Le informazioni contenute in queste pagine sono state sinora garantite dalla disponibilità del personale, precario e non dell’Istituto Nazionale di Geofisica e Vulcanologia. L’agitazione del personale dell’Istituto contro l’emendamento 37bis alla proposta di legge 1441 quater, che in sostanza provocherebbe il quasi immediato licenziamento del personale precario, porterà alla sospensione di tutte le attività. Nell’immediato si procederà al blocco di ogni tipo di informazione telematica e telefonica non istituzionale.
Ma torniamo un attimo alle tre regole di sopra. La prima può sembrare meno importante, ma nasconde nella sua semplicità di formulazione un grande potere (sembra Spiderman).
Usiamo ogni giorno gli indirizzi http, gli URL. Li usiamo in modo naturale e spontaneo, senza chiederci cosa siano, su cosa si basino e come funzionino. E non c’è nulla di male.
Quando cambio canale della mia TV con un telecomando, non devo avere alcuna nozione sulla trasmissione dell’infrarosso; devo soltanto saper che devo usare un determinato tasto. Se prendo il telecomando del mio nuovo stereo, mi viene naturale utilizzarlo allo stesso modo. Così per il lettore DVD e per la mia pompa di calore (dite che questa è una forzatura?).
Anche accedere a diversi tipi di dati, di diversa origine, dovrà essere una cosa così semplice e “spontanea”. Con lo stesso protocollo, l’http, non più accedere “soltanto” a pagine web ma anche a fonti di dati grezze.
Quello che gli eventi abruzzesi mi hanno stimolato, come uomo e come professionista, è l’attenzione alla politica della gestione dei dati. Le classi dirigenti del nostro paese dovrebbero allinearsi a quanto esposto da Tim Berners-Lee. Sia perché il cittadino possa essere informato, sia per dare forza e valore ai dati, i quali se chiusi in un hd o divulgati in modo inappropriato rischiano di essere inutili e di produrre uno spreco (non soltanto economico).
Dobbiamo tenere alta l’attenzione verso questi temi.
I fatti di questi giorni, il dialogo con i colleghi di TANTO, l’indiretto stimolo di Alessio, i post di altri blogger, mi hanno spinto anche a provare a realizzare una piccola cosa concreta, proprio a partire dai dati sismici della regione Abruzzo.
Si tratta di qualcosa che a prima vista è confrontabile alle interfacce di webmapping basate su Google Maps, in cui in coincidenza della posizione di ogni evento sismico è raffigurato un “pallino”. Quello che ho provato ad aggiungere è la possibilità di modificare e “mescolare” i criteri di visualizzazione del dato: a partire dalla serie di dati che ho estratto, poter visualizzare ad esempio soltanto gli eventi sismici di Marzo, di magnitudo maggiore di 4, di profondità compresa tra 5 e 10 km e del distretto sismico del “Gran Sasso”. L’utilizzo di questi filtri mi ha dato (da utente) la sensazione di potere leggere “meglio” i dati; spero che non dipenda dall’emotività con cui ho lavorato su questo piccolo progetto.
Ho aggiunto anche una timeline, che da la possibilità di passare dalla visualizzazione degli eventi in scala spaziale, ad una efficacissima in scala temporale. Anche qui potrete usare gli stessi filtri. C’è una visualizzazione tabellare “dinamica” in HTML, ordinabile usando qualsiasi delle colonne presenti, ed anche questa “sensibile” ad i filtri.
Infine i dati sono esportabili in diversi formati, tra i quali: RDF/XML, Semantic wikitext, Tab Separated Values. Per attivare l’export basta andare con il mouse alla sinistra del modulo “Cerca”, e cliccare sull’icona a forma di forbice che verrà visualizzata (vedi figura).
Purtroppo ho riscontrato un problema con l’export nel formato a cui tenevo di più – RDF/XML – ma spero di risolverlo nei prossimi giorni (è un piccolo autogol ).
L’interfaccia sviluppata ha però un vero grande difetto (e magari non sarà l’unico): non si aggiornerà in automatico, ogni volta che verranno pubblicati nuovi dati dall’INGV. Questo perché sono partito dai quelli pubblicati qui (una tabella HTML), e non da quelli in CSV o KML. Nei prossimi giorni proverò a partire da quelli in CSV, darli in pasto a Yahoo! Pipes ed automatizzare il processo di pubblicazione.
L’applicazione è visibile qui, e qui sotto vedete uno screenshot della timeline.
E’ realizzata con Exhibit, e ci scriverò a breve un tutorial di dettaglio. In questo post volevo “fare” altro.
Chiudo dando la disponibilità di collaborazione mia e dei miei colleghi, a chiunque ritenga che le nostre competenze possano essere d’aiuto in questo momento.
Un abbraccio forte a tutti quelli che stanno vivendo questo terribile momento; uomini, donne e bambini con una compostezza ed una dignità fuori dal comune.
Lezioni online per spiegare scienza e tecnologia Oilproject organizza con l’Istituto Italiano di Tecnologia una serie di lezioni divulgative su neuroscienze, nanotecnologie, farmacologia e macchine intelligenti, per raccontare al grande pubblico lo stato dell’arte della ricerca di base e applicata. Qui tutti i dettagli. Leggi tutto... (0)
Il GFOSS Day 2011 è a Foggia I prossimi 24 e 25 novembre l’Università degli Studi di Foggia ospiterà il GFOSS DAY 2011, organizzato come di consueto dall’Associazione Italiana per l’Informazione Geografica Libera GFOSS.it Leggi tutto... (1)
Mappali, denunciali e... tassa.li Tassa.li è una interessante startup realizzata da un gruppo di giovani tecnologi, con l’intento di rendere facile la denuncia di esercizi commerciali che non rilasciano il regolare scontrino fiscale. E in un periodo nero come questo, molta gente avrà una gran voglia di partecipare. Grazie a una applicazione disponibile sia per iOS che Android, è infatti possibile in pochi clic geotaggare l’esercizio e riportare la somma dello scontrino non emesso. Il tutto in maniera assolutamente anonima. E questi ragazzi dimostrano di vedere molto lontano, perché presto rilasceranno i dati raccolti in forma totalmente aperta e libera. (7)
TANTO non rappresenta una testata giornalistica ai sensi della legge n. 62 del 7.03.2001, in quanto non viene aggiornato con una precisa e determinata periodicita'. Pertanto, in alcun modo puo' considerarsi un prodotto editoriale.