Giuseppe: Oggi parliamo tanto di “cittadini sensori“, di Citizen Science, di crowdsourcing e, in poche parole, del coinvolgimento attivo da parte dei cittadini in progetti di raccolta dati (georeferenziati) sul terreno, per progetti di ricerca o di pubblica utilità.
Sappiamo che tali iniziative sono possibili in misura sempre maggiore grazie a delle “rivoluzioni” che ci hanno coinvolto molto da vicino e relativamente molto recenti. L’aumento della velocità di trasmissione dati su Internet, l’abbassamento dei costi legati alle tecnologie ICT, la disponibilità di sistemi di localizzazione GNSS (GPS e altri) a basso costo e di buona precisione (almeno per applicazioni diverse da quelle geodetiche!) e lo sviluppo di smartphone e Social Network hanno senz’altro reso più facile e veloce l’interazione tra individui dotati di dispositivi “smart”, tra loro e con piattaforme di condivisione di dati e informazioni.
Questo è senz’altro vero, ma iniziare a raccogliere dati geolocalizzati in maniera ordinata e sistematica e c ondividerli alla fine del processo richiede nella maggior parte dei casi un po’ di doti di programmazione o quanto meno di familiarità avanzata con strumenti di tipo informatico.
Tale premessa è alla base di quanto abbiamo cercato di sviluppare, a partire dall’estate del 2015, con i ragazzi dell’insegnamento di Geografia delle Reti, nell’ambito dei Corsi di Laurea Magistrali in “Scienze Economiche” e “Scienze Aziendali ” dell’Università di Trieste.
L’idea di partenza era quella di sperimentare modalità di crowdsourcing nell’acquisizione di dati geografici relativi a fenomeni urbani su piattaforme una soluzione senza costi di licenza e con un limitato ricorso a doti di programmazione.
Viola: Oltre ad una soluzione a basso costo e di relativa semplicità nell’impostazione del questionario, volevamo uno strumento che, oltre
a poter registrare dati sotto forma di punti, polilinee o poligoni, avesse queste caratteristiche:
- relativa applicazione scaricabile (gratuitamente) su smartphone;
- permettesse la compilazione del questionario anche in caso di assenza di rete;
- permettesse di caricare un numero molto elevato di risposte da vari dispositivi (o comunque un numero in linea con le nostre esigenze);
- fosse compilabile via sito web (in caso di problemi di compatibilità con il sistema operativo del telefono o in presenza di qualche buon’anima ancora dotata di Nokia 3310 come arma di battaglia!)
Potrebbero sembrare delle premesse un po’ pretenziose ma dopo varie ricerche, qualche decina di download (wi-fi permettendo) a causa di una rete casalinga un po’ ballerina, qualcosa abbiamo trovato.
Ci siamo imbattuti nella “galassia” di Open Data Kit, un progetto “open” che consente l’impostazione di sistemi client-server di raccolta
e archiviazione di dati da parte di operatori sul campo tramite dispositivi mobili.
Dal sito (https://opendatakit.org/) si legge che ODK (dove ODK sta per Open Data Kit, nel caso ve lo stiate chiedendo) è un “free and open-source set of tools which helps organizations author, field, and manage mobile data collection solutions“, che consente di:
- costruire una form (o “questionario”) di raccolta dati;
- raccogliere dati su di un dispositivo mobile;
- aggregare i dati raccolti su di un server ed estrarli in formati utilizzabili.
Giuseppe: Open Data Kit inizialmente si è sviluppato basando su Google la gestione del proprio “lato server”, dopodiché si è affrancato dal mondo ”commerciale” basandosi soprattutto su architetture open source.
Il sistema richiede diversi elementi, esemplificati nell’immagine qui sotto, da integrare.
Innanzitutto una form, ovvero il questionario da sviluppare.
Una ‘piattaforma’ per la raccolta dei dati: qui ci viene in aiuto enketo.org per la realizzazione di una webform compilabile da (virtualmente) qualsiasi dispositivo, oppure un’app da caricare su dispositivo mobile. Diverse app sono state sviluppate: ODK Collect e KoBo Collect, solo per citarne un paio, soprattutto nell’ambito di progetti a contenuto umanitario o sviluppati apposta per scopi educativi.
Un server, ovvero un sistema centralizzato in cui salvare i dati immessi. Senza ricorrere a un nostro server si può fare riferimento alle piattaforme ODK aggregate e Ona.io.
Viste le applicazioni alternative basate sulla stessa base ODK, abbiamo scelto GeoODK perché ci è sembrata la più semplice e completa, perché consente anche la modifica dei dati prima dell’upload su una base cartografica digitale e di caricare sul dispositivo dei layer geografici ad hoc (non necessariamente le basi di sfondo tipo OpenStreetMap) – funzionalità non implementata nell’esempio che abbiamo riportato in questo report.
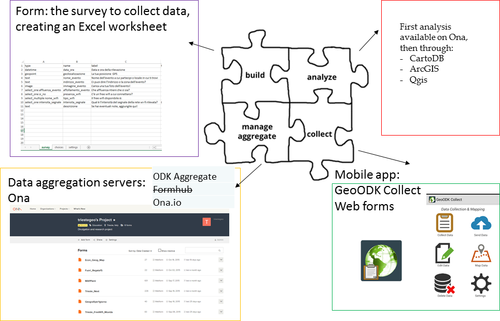
Il Sistema ODK (Open Data Kit) e le sue componenti
Inutile dire che, per i nostri scopi, l’attenzione era rivolta alla raccolta di dati georeferenziati, sfruttando il GPS interno per geolocalizzarsi. Il
sistema ‘ODK’ offre numerose app già pronte utili per la raccolta dei dati, come ODK Collect e KoBo collect. Queste tuttavia consentono soltanto di caricare dati geografici sotto forma di punti (coppie di coordinate) e hanno un’interfaccia molto semplice e tutto sommato limitata, senza grandi possibilità di editing e visualizzazione dei dati sul dispositivo mobile.
Viola: L’applicazione scelta è stata GeoODK, dove il “Geo” sta per Geographical (Open Data Kit), sviluppata sempre a partire dalla piattaforma ODK, ma con un’attenzione maggiore al lato geografico.
In particolare consente varie cose in più rispetto a ODK, ovvero:
- è più semplice;
- consente di visualizzare e modificare i dati prima dell’upload su una base digitale sullo smartphone o tablet;
- consente di caricare localmente dei layer geografici ad hoc (non necessariamente le basi di sfondo tipo OpenStreetMap) – funzionalità non implementata nell’esempio riportato;
- consente di registrare, anche tramite form, dati sotto forma di punti, polilinee o poligoni (funzioni “geopoint”, “geotrace” e ”geoshape”).
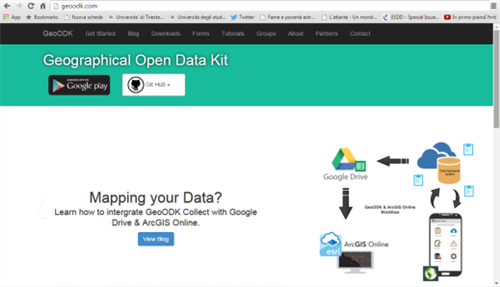
GeoODK permette di strutturare un questionario tramite un semplice file Excel (se vedete la parola “form” più avanti non vi spaventate, ci riferiamo a questo) e qualche piccola accortezza, fornendo già sia la propria applicazione mobile sia una soluzione “lato server” per l’aggregazione dei dati, individuata inizialmente in Formhub, dopodiché (a causa della sua lentezza e dell’abbandono da parte degli sviluppatori) trovata nella piattaforma ona.io (anche questa in seguito non più disponibile completamente free). L’alternativa “locale” rimane sempre ODK Aggregate, da installare su di un proprio server.
Mentre la seconda soluzione è più laboriosa, richiedendo di caricare ODK Collect sul proprio server (per il momento ci stiamo pensando ma non abbiamo ancora messo in pratica di sfruttare il server dell’Università di Trieste e il nostro adorato informatico A.P.), Formhub era già bello e pronto e richiedeva solo l’iscrizione (ovviamente gratuita) dell’utente. Problema incontrato già al momento della scelta di utente e password: il server faceva venire i sudori freddi. Era in sovraccarico un buon 70-80% delle volte in cui ci si connetteva e si aveva bisogno di lui. Qualche settimana fa poi il server non è definitivamente più aggiornato dall’organizzazione che se ne occupava quindi ve lo sconsigliamo proprio.
Il sito web http://geoodk.com/tutorials.php contiene un buon videotutorial su come impostare i diversi elementi di un progetto di Mobile Data Collection, presentati al GIS Day 2014. Da quello siamo partiti per il nostro lavoro, e qui sotto cerchiamo di sintetizzarlo un po’ a un pubblico italiano.
Dopo un paio di mesi di stress ed incubi causati dai continui problemi di sovraccarico di Formhub, a settembre il magico prof (Giuseppe) ha trovato un nuovo server su cui caricare i dati. Stesso layout di Formhub, stesse funzioni… la copia conforme ma rapidissima: Ona.io.
Così, un’altra registrazione più in là siamo finiti su un altro server felici e contenti come pasque. Escludendo il fatto che il primo ottobre hanno rilasciato una nuova piattaforma dal diverso layout per cui abbiamo avuto entrambi un colpo al cuore…temevamo di aver perso tutto!
In realtà abbiamo scoperto che dal 21 ottobre cambiano i termini di utilizzo e, in verità, il sito è stato migliorato e con le attuali condizioni è possibile avere un account gratuito caricando fino a 15 questionari e ricevendo fino a 500 risposte al mese, che tutto sommato – poi dipende dall’uso che si vuole fare- sono un buon numero.
LA SETTIMANA PROSSIMA IL SEGUITO …
Nasco geografo economico, mi interesso di Geographic Information e di Smart Cities. Attratto dalle tecnologie ICT e dall’innovazione, ma sempre con l’uomo al centro. Professore di Economic Geogrphy, GIS e Geografia delle Reti. Presidente del Comitato Scientifico dell’Associazione Italiana di Cartografia. Nel tempo libero, poco, running o MTB
Fresca fresca di laurea magistrale in Scienze Aziendali, ho scoperto “all’ultimo minuto” una passione per Smart Cities, GIS e Citizen science, di cui ho scritto per il lavoro di tesi. Sono fermamente convinta che non esistano Smart Cities senza Smart Citizens e che la tecnologia sia un mezzo e non un fine per migliorare le città.