Archivio per la categoria ‘osgeo’
3 aprile, 2013 | di redazione
Il tema degli OpenGeoData è importante e pensiamo che meriti hic et nunc un’attenzione speciale. E’ indispensabile la crescita di una consapevolezza diffusa del loro valore, così come è necessario porre l’attenzione sulle modalità di implementazione del modello e verificarne l’impatto in termini di valore aggiunto; per professionisti, aziende, decisori e cittadini.
Vogliamo creare un gruppo di lavoro aperto a tutti e che si appoggerà anche su quanto di buono e utile è stato fatto in analogia per il tema più generale degli OpenData.
Tre i temi principali che, in questa prima fase, vorremmo trasformare in azione:
- Formazione – iniziative formative a medio, lungo termine riguardanti la formazione su specifiche questioni di fondo (metadati, INSPIRE, standard, soluzioni tecnologiche, ecc.).
- Informazione – iniziative di tipo divulgativo (filmati didattici e di promozione), così come webinar di taglio informativo su argomenti di approfondimento.
- Buone prassi – segnalazione e report di iniziative e progetti riguardanti geoportali e portali open data, standard, apertura e liberazione di dati (ma non solo) che possono essere prese a modello.
Pensiamo sia necessario il contributo di molti, sia in termini di contenuti che di modalità di azione. Per questa ragione abbiamo pensato di creare uno spazio in cui ognuno potrà proporre, condividere, commentare e valutare in modo costruttivo idee utili sul tema.
E’ stata aperta una community su ideascale (geodatiliberi.ideascale.com), non vi resta che aprire un account e cominciare a proporre e interagire con gli altri. Troverete le tre categorie di cui sopra nelle quali inserire le idee e proposte, in modo tale da rendere il tutto più organico. A supporto di questo ideario, è stata creata anche una mailing list.
Perché OpenGeoData non sia soltanto un obbligo normativo, una moda o un sfogo per il “geogeek“.

immagine realizzata a partire dalla foto di Diego Dalmaso
Insieme a :
Posted in Entropia, osgeo | No Comments »
18 febbraio, 2013 | di Andrea Antonello
Nel corso del 2012 ho avuto il piacere di collaborare al progetto FreeGIS. Il mio compito è stato quello di testare l’usabilità di un particolare software di mappatura di schemi di dati per mappare e successivamente convertire un set di dati della provincia di Bolzano verso lo schema di dati INSPIRE.
Considerato che ogni volta che scrivo la parola INSPIRE mi tremano le mani e ogni volta che ne parlo mi trema la voce, è stata un’esperienza interessante, anche al fine di smitizzare e abbattere alcuni muri, nonché confermare alcune assurdità che la complessità degli standard porta inevitabilmente con sé.
La certezza che ora ho è che la migrazione di dati verso gli schemi INSPIRE è una procedura molto complessa, ma non impossibile, e che richiede freddezza nella preparazione e personale capace e aggiornato da un punto di vista tecnico.
Io in generale non credo ai software dall’unico pulsante magico.
Credo però nel senso di una procedura guidata. Credo in un software che possa semplificare i passaggi importanti di tale procedura, supportando soprattutto la leggibilità degli schemi di dati e la consistenza delle mappature che si vanno ad operare.
Humboldt & Hale
Il software che ho avuto modo di testare (e poi anche estendere) si chiama Humboldt Alignment Editor (Hale per gli amici) e nasce da un progetto europeo che ha coinvolto 26 partner fra il 2006 e il 2011 (fra i quali gli italiani di CNR-IREA, GISIG, Telespazio e dell’Università di Roma). Il progetto Humboldt si è occupato principalmente dell’armonizzazione dei dati a livello europeo. Data la moltitudine e diversità dei dati presenti nelle varie organizzazioni europee, naturalmente non si trattava di re-inventare la magia nera, bensì di creare strumenti che potessero supportare il processo di implementazione.
Dal progetto Humboldt è nato il Data Harmonization Panel (DHP), una piattaforma di esperti nell’armonizzazione dei dati spaziali. Lo stesso DHP si pone tutt’oggi due importanti obiettivi:
- lo sviluppo ed il supporto degli strumenti sviluppati in Humboldt
- il supporto di un framework di formazione
Del progetto Humboldt oggi viene sviluppato in modo attivo praticamente solo la componente Hale. Il progetto è rilasciato con licenza Free ed Open Source alla community per facilitarne l’interazione ed il miglioramento.
E’ proprio la natura open del progetto che mi ha portato prima ad avvicinarmi a Hale attraverso FreeGIS e poi, in un secondo momento, quando ho avuto il piacere di essere chiamato a svilupparne alcune funzionalità nel team geospaziale del Fraunhofer IGD (attuale centro di coordinamento del progetto).
E’ stata questa collaborazione che mi ha ispirato a scrivere un articolo riguardante Hale in modo da renderlo un pochino più noto al di fuori della cerchia accademica e dei progetti europei.
Ma bando alla storia e passiamo alla parte pratica.
Utilizzare Hale
Per mostrare il funzionamento di base di Hale mi rifarò in parte al progetto FreeGIS usando i dati della Provincia di Bolzano e descritti nel eGeo, il geoportale della provincia. Mi riferirò in particolare al set di dati di quello che è definito in INSPIRE RoadLink dello schema dei TransportNetwork.
Per chi volesse cimentarsi, è possibile scaricare Hale dall’area di download del sito del progetto per i sistemi operativi più diffusi.
Una volta lanciato, Hale si presenta in questo modo:
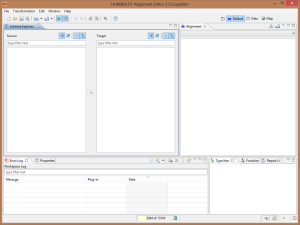
Le parti più importanti sono indubbiamente le viste dello Schema explorer e dell’Alignment.
Hale è stato concepito per mappatura di strutture di dati molto complesse, fra schemi di dati xml come lo possono essere ad esempio gli schemi CityGML. Il nostro esempio non renderà onore a questo potenziale, in questa sede si vuole piuttosto introdurre lo strumento in generale.
Definire lo schema di arrivo
La prima cosa da definire, è lo schema verso il quale si desidera mappare lo schema dei dati originali. Nel nostro caso si parla di dati del TransportNetwork, quindi è necessario caricare lo schema xml del RoadTransportNetwork di INSPIRE. Tale schema è scaricabile qui.
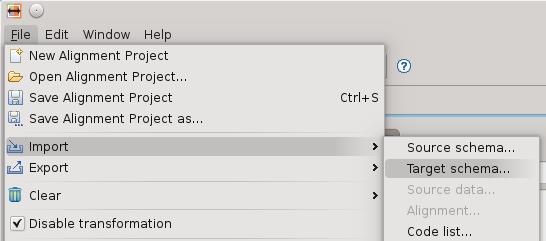
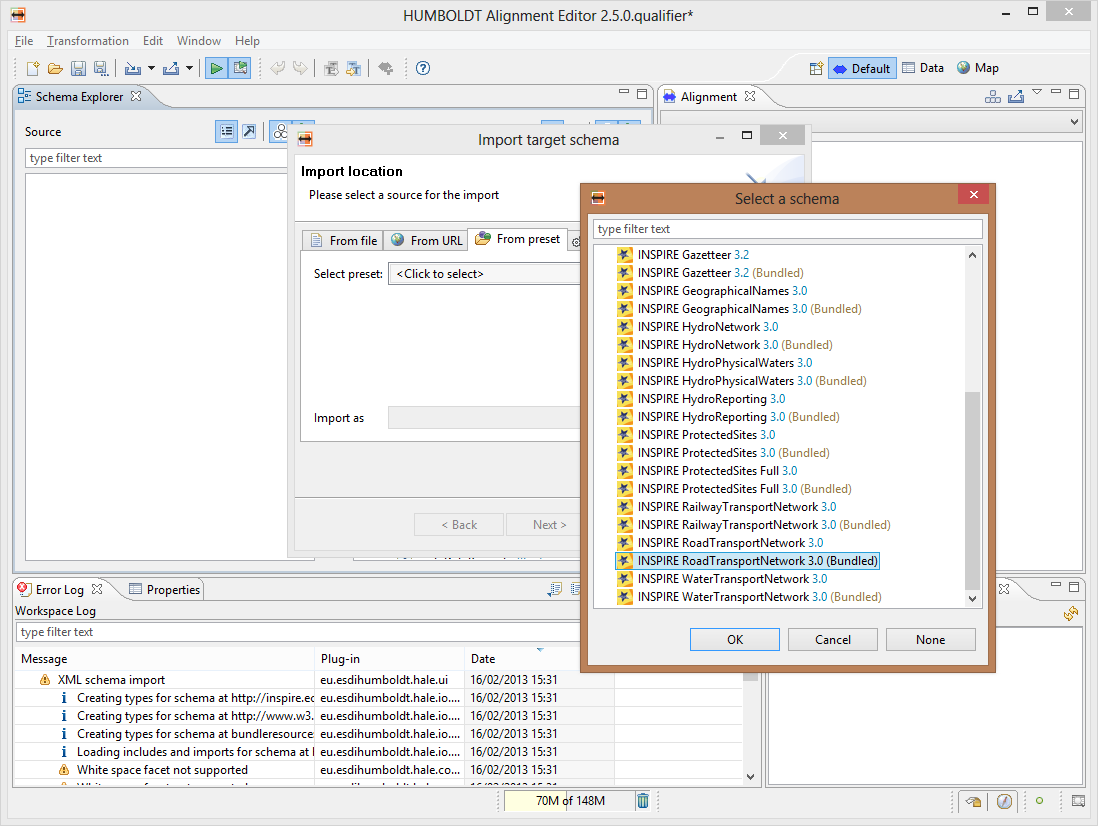
Una volta scaricato sul proprio disco rigido, è possibile importarne la definizione dal menu di import attraverso l’operazione target schema:
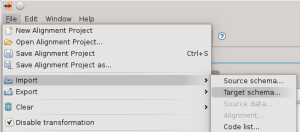
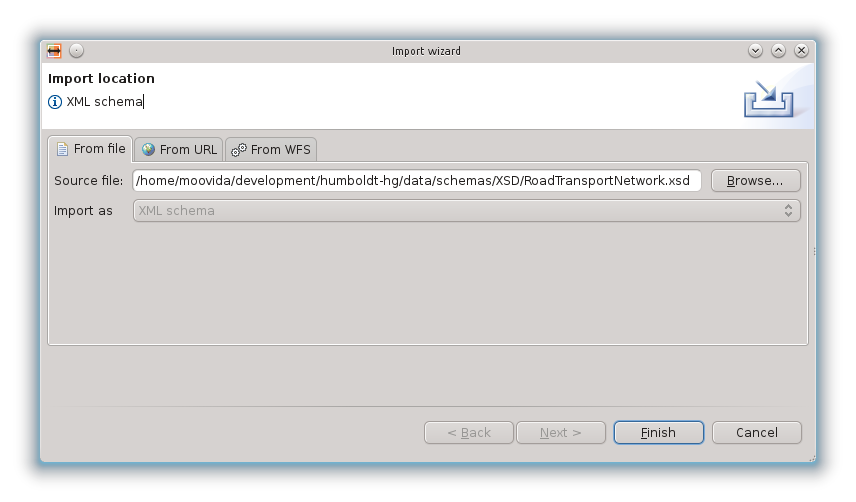
definendo poi nella procedura guidata il file da importare:
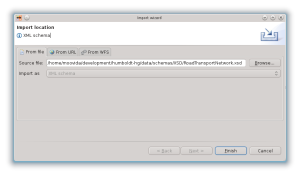
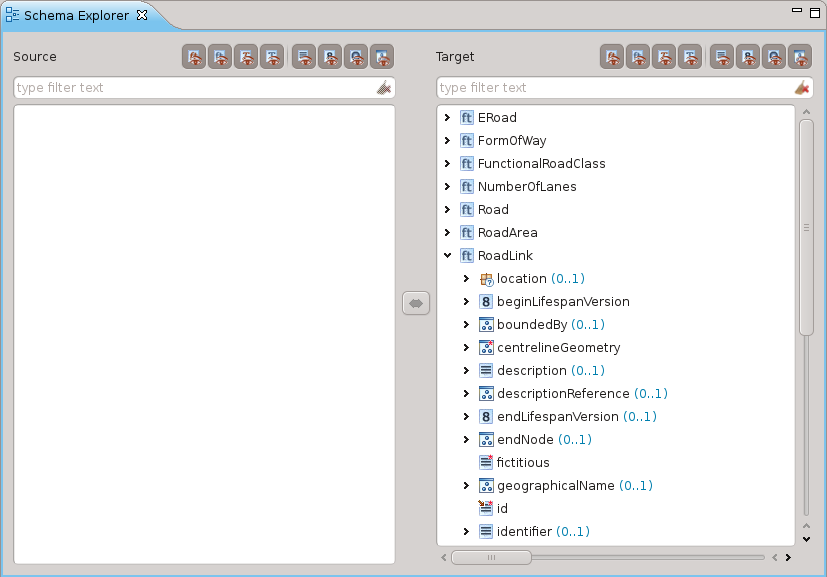
per poi trovarsi lo schema visualizzato nella sua struttura ad albero in Hale:
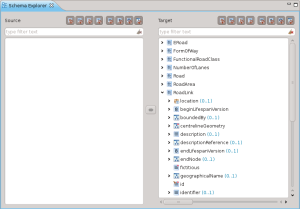
Da poco sono stati aggiunti alcuni schemi preconfigurati legati a INSPIRE, che si possono trovare nella tab denominata presets. Nel nostro caso lo schema di interesse è presente:
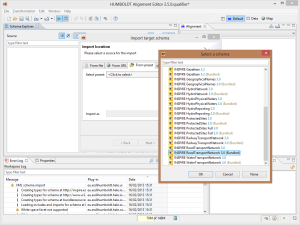
Definire lo schema di partenza
La definizione dello schema di partenza può essere una procedura semplice o molto complessa, dipendentemente dal formato in cui si sono mantenuti i propri dati (e questa è indubbiamente una scienza a parte). Hale permette l’import dello schema da file, ma anche da servizi WFS. Per set di dati molto semplici è possibile generare uno schema estraendolo da shapefile.
Come per il target schema, partendo nuovamente dal menu di import, procediamo ad importare il source schema:
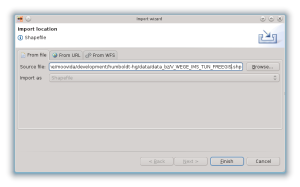
per trovarci con la seguente situazione:
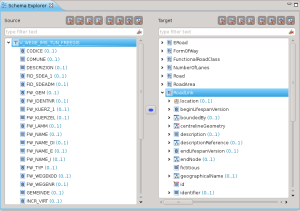
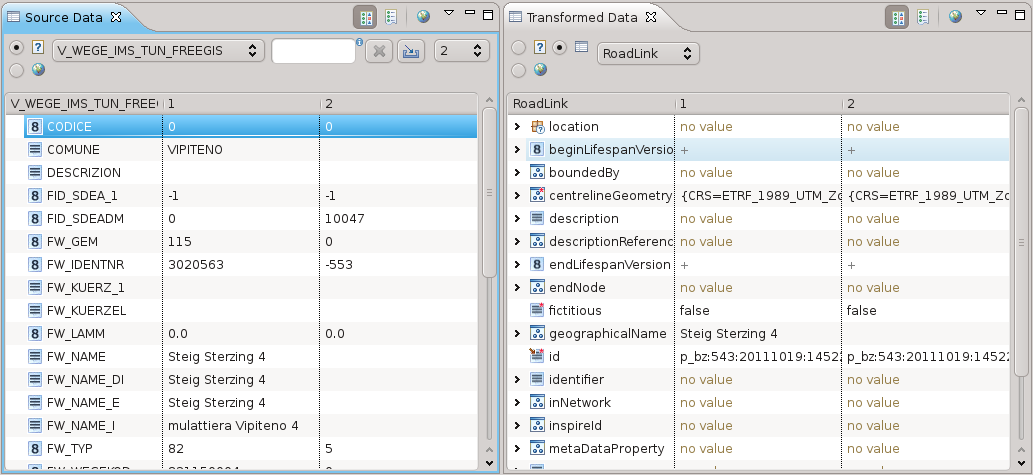
Nell’immagine la selezione è stata poi posizionata sui due tipi da mappare.
Come mappare gli schemi
Mappatura del tipo
La prima operazione da fare, è quella della mappatura dei tipi principali, in questo caso V_WEGE_IMS_TUN_FREEGIS verso il RoadLink INSPIRE.
Il dato di partenza pero’ contiene tutto il transport network (strade, ferrovie, etc), quindi bisogna procedere a creare una regola per estrarre solo le strade.
Con un GIS questa operazione è abbastanza triviale. In uDig l’operazione può essere fatta con il linguaggio CQL (Constraint Query Language).
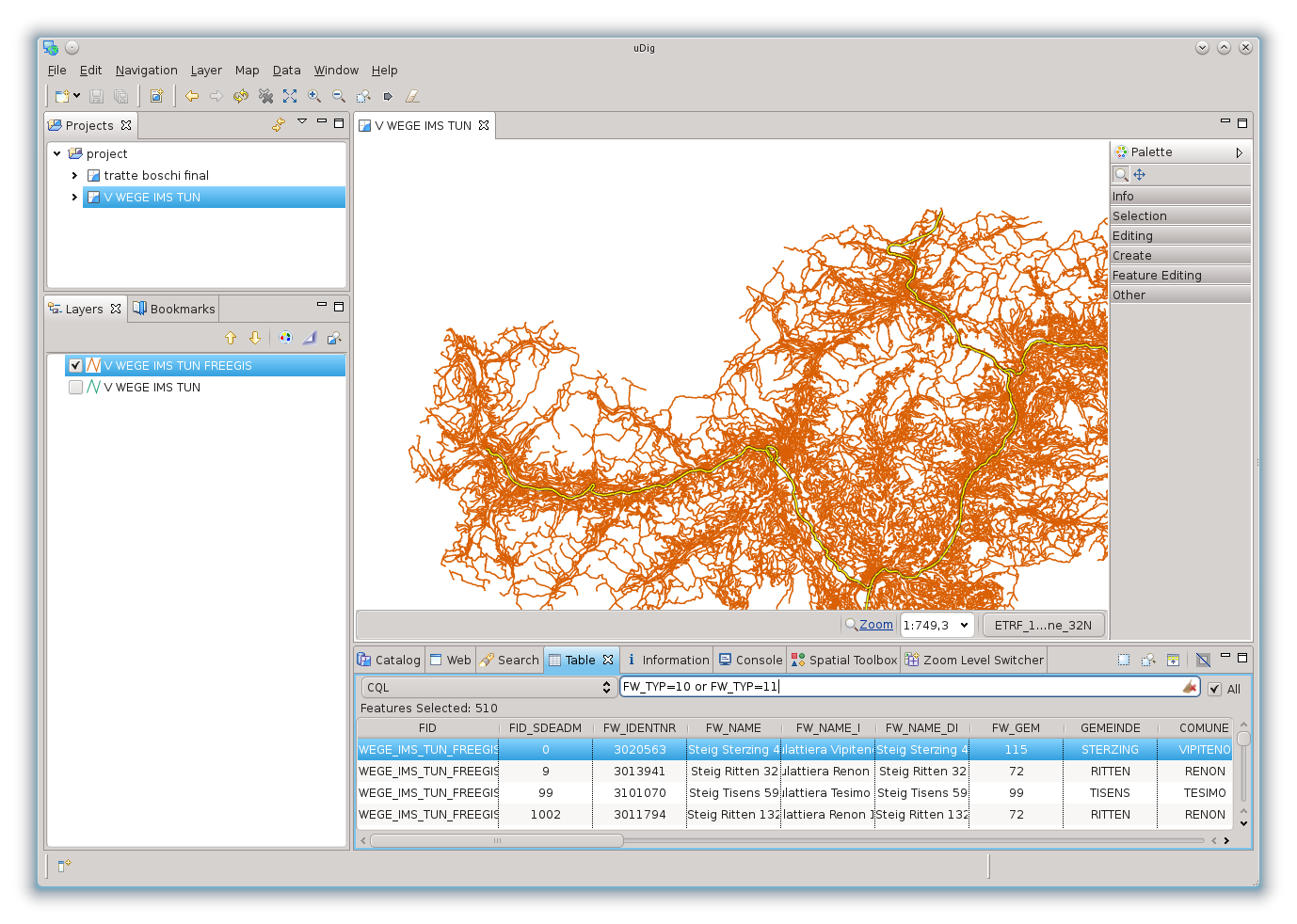
Ad esempio ponendo delle condizioni sul campo giusto possiamo isolare le ferrovie:
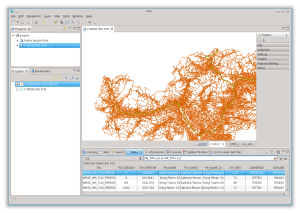
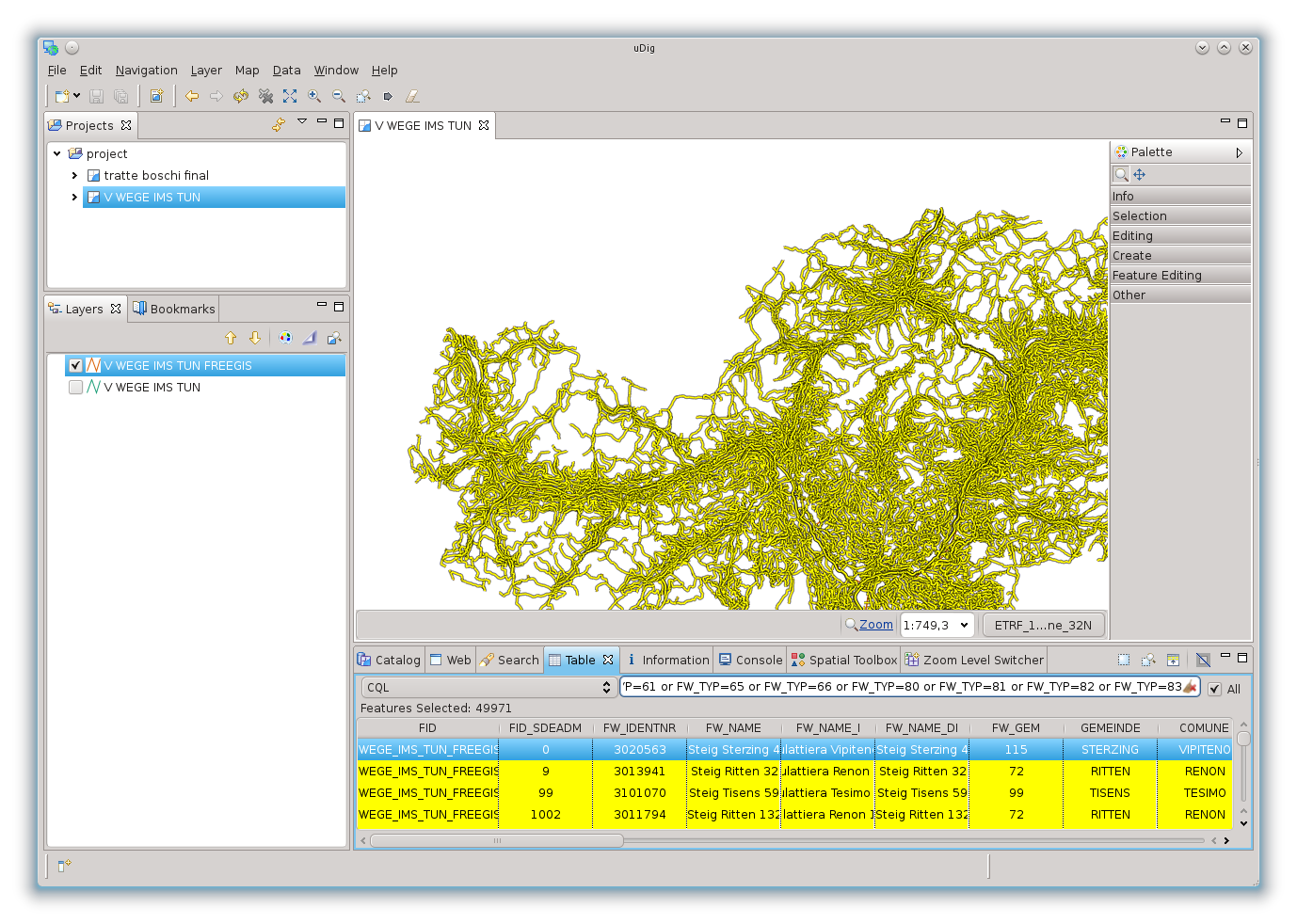
oppure, cosa necessaria al nostro esempio, le strade:
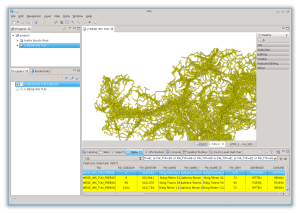
Il motivo per il quale vi cito uDig è duplice. Perché è il GIS con il quale lavoro e che supporto in modo attivo, ma anche perché Hale supporta lo stesso identico linguaggio CQL.
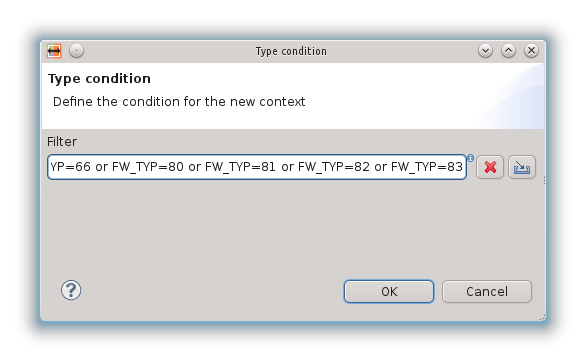
E’ quindi possibile creare un condition context:
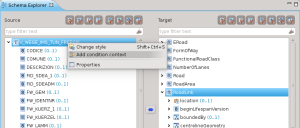
usando come condizione esattamente la stringa testata in uDig:
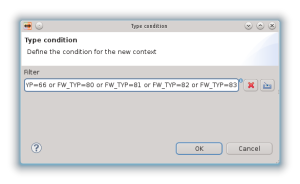
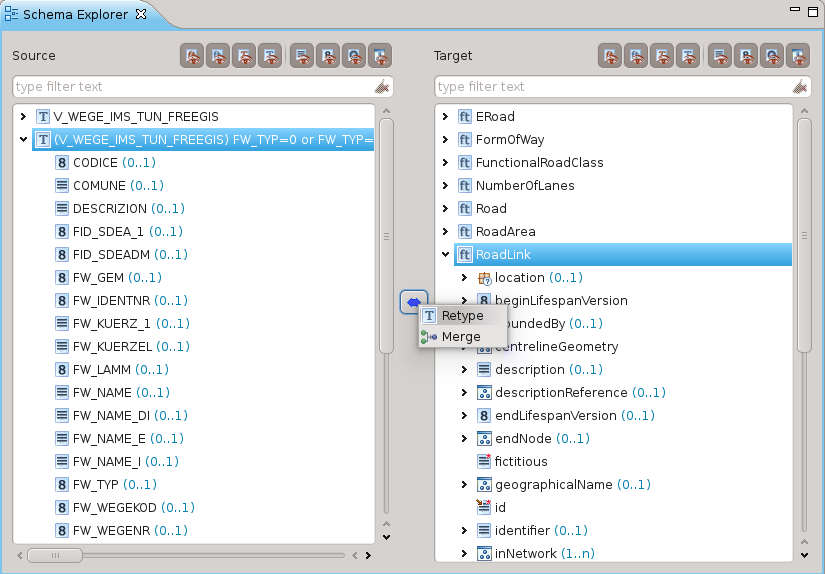
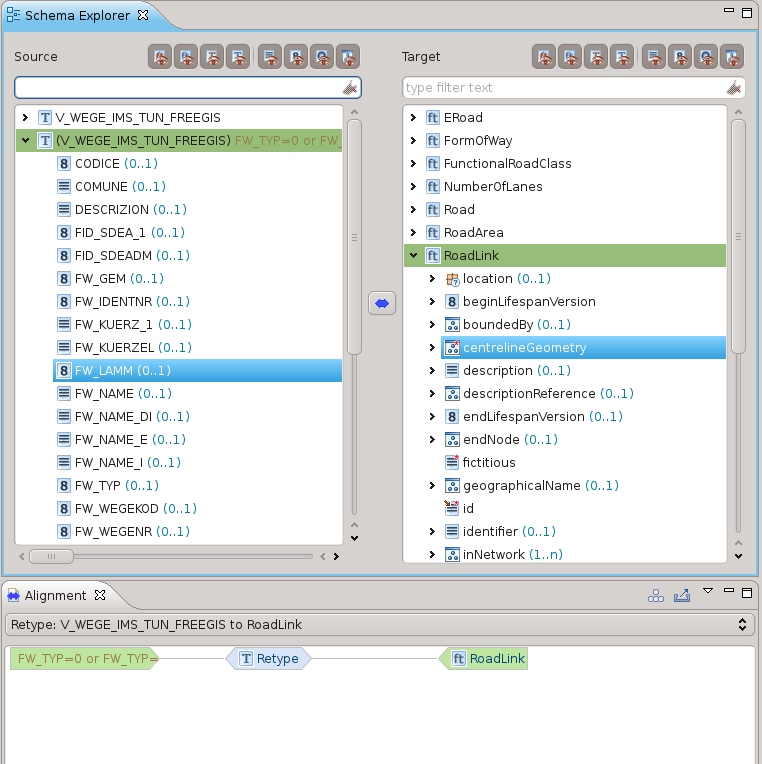
A questo punto Hale crea un nuovo tipo in base alla condizione imposta e sarà quello che verrà mappato attraverso un’operazione di Retype:
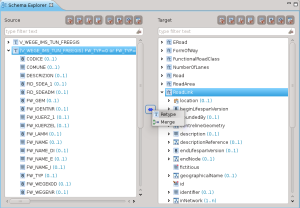
Una volta conclusa la procedura guidata, la mappatura sarà visualizzata nello schema explorer e nella vista dell’Alignment:
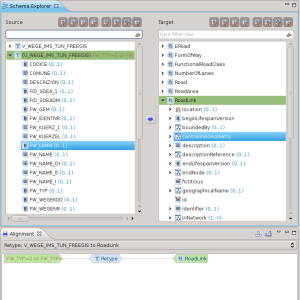
Mappatura degli attributi
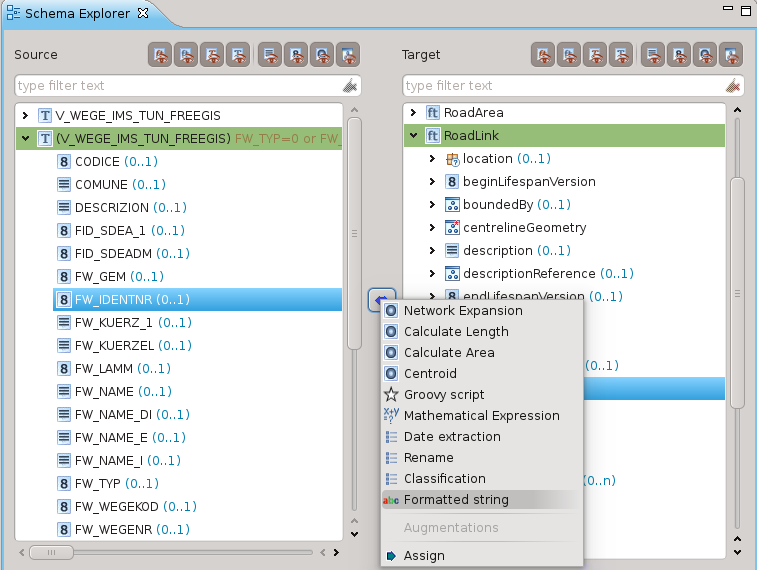
Non voglio tediarvi con la descrizione dei vari attributi, quindi riassumerò solo alcune operazioni che si possono applicare per la mappatura degli attributi
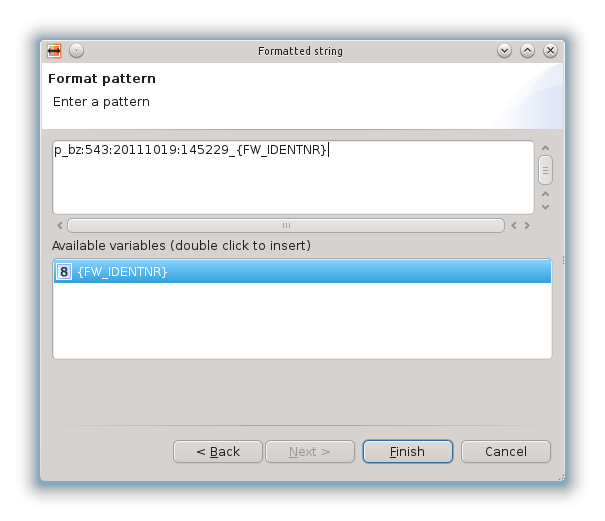
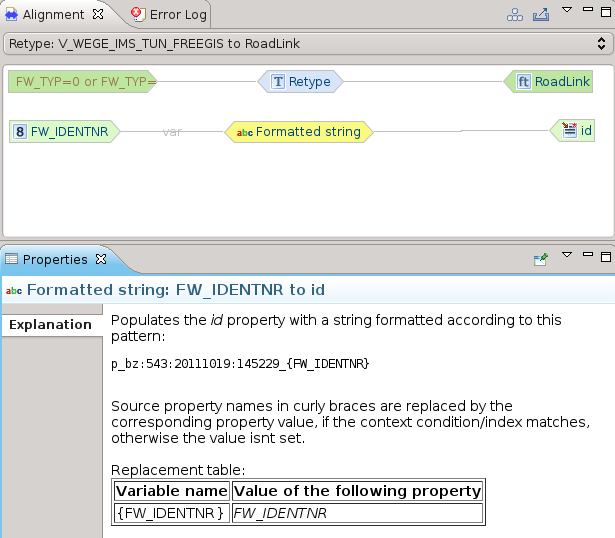
Formattazione di stringhe
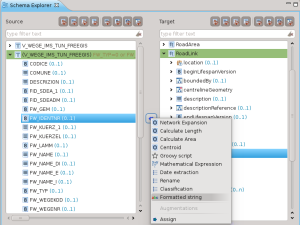
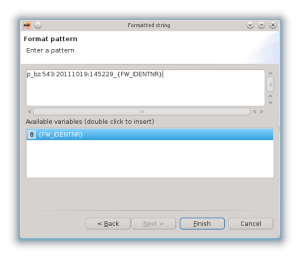
Permette di concatenare le stringhe dei diversi campi dello schema di partenza e delle costanti aggiunte manualmente per creare una stringa nello schema di arrivo:
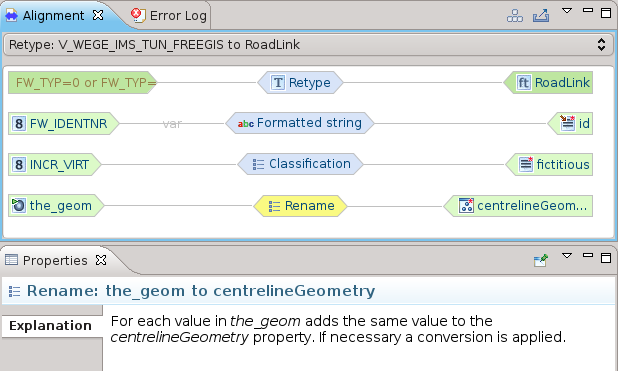
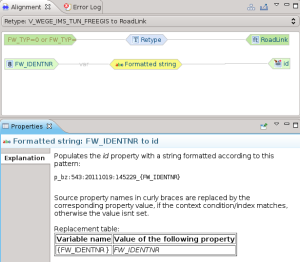
Appena applicata la mappatura, viene visualizzata nella Alignment View e la vista delle proprietà ci fornisce una descrizione dell’operazione applicata:
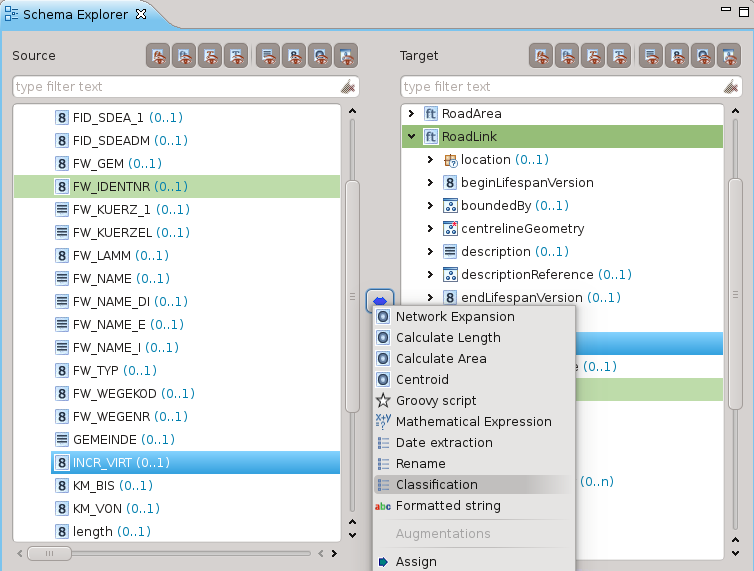
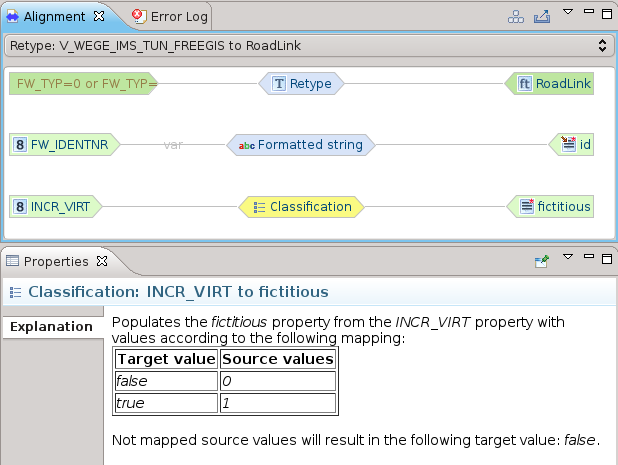
Classificazione
La classificazione è forse una delle operazioni più importanti, permette di mappare classi di valori.
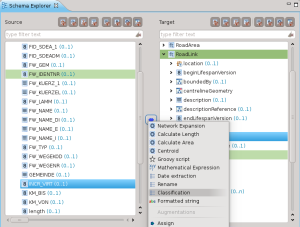
Un esempio molto semplice è la mappature fra dei valori interi 0/1 al loro booleano nello schema di arrivo:
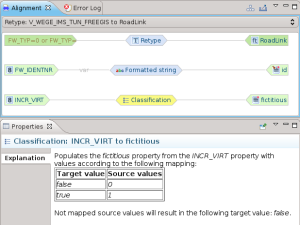
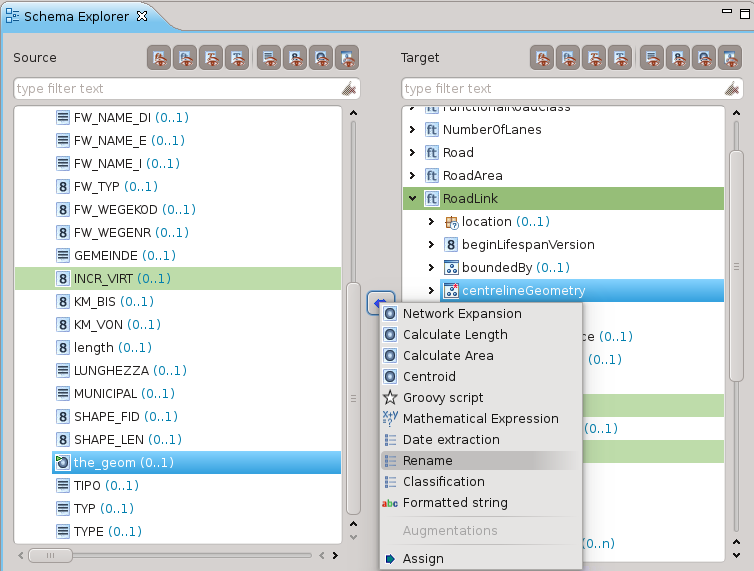
Mappatura della geometria
E’ possibile eseguire la mappatura di geometrie:
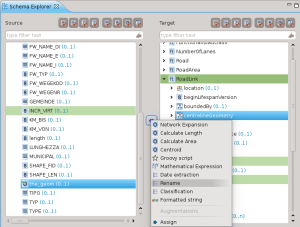
Il tipo nel nostro caso è lo stesso, quindi una operazione di rename è sufficiente:
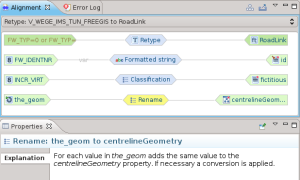
Non mi spingo oltre con la descrizione del processo di mappatura. Accenno solo al fatto che è possibile utilizzare anche degli script, cioè dei frammenti semplificati di programmi, che rendono possibili trasformazioni personalizzate molto complesse.
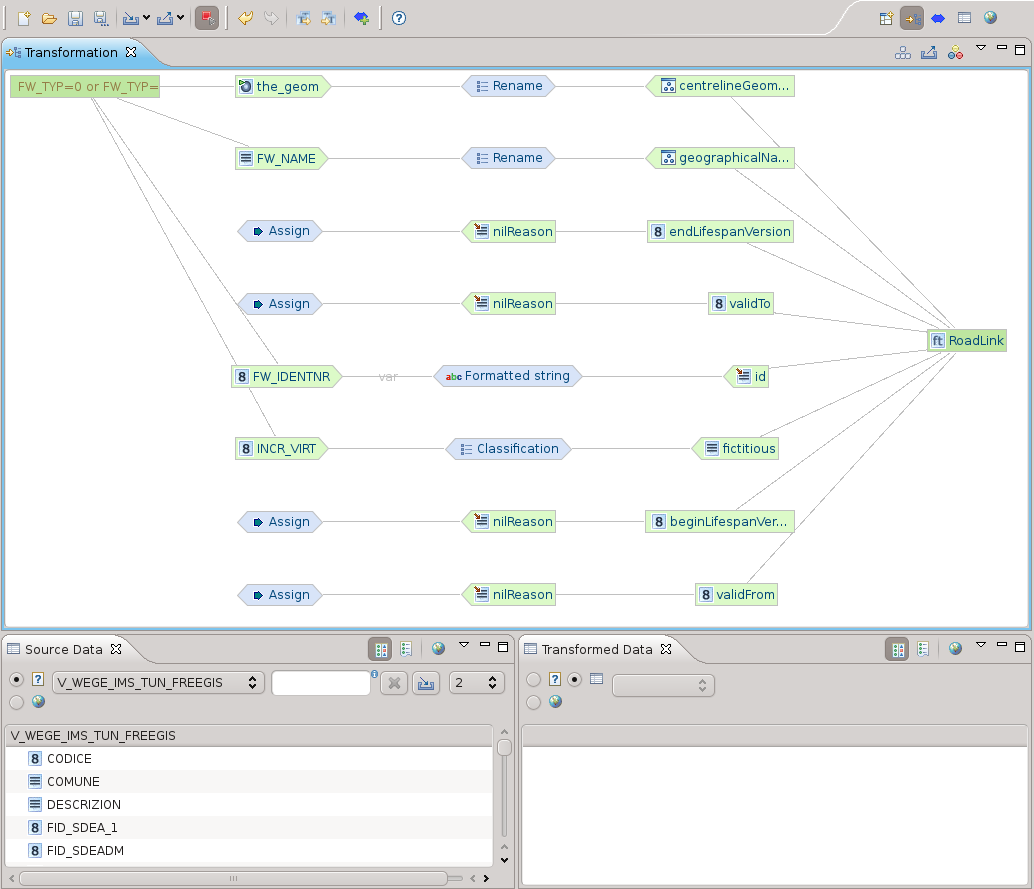
Controllo mappatura e trasformazione dati
Una volta conclusa la mappatura, la vista delle trasformazioni è quello che fa per noi. Ci permette di dare una controllata finale al grafico della trasformazione
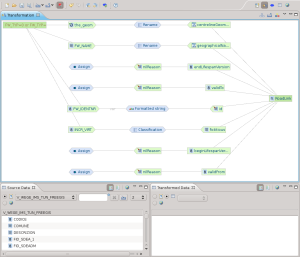
e la possibilità di caricare un set di dati per eseguire una trasformazione secondo la mappatura precedentemente prodotta.
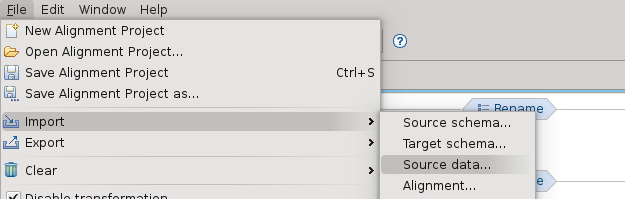
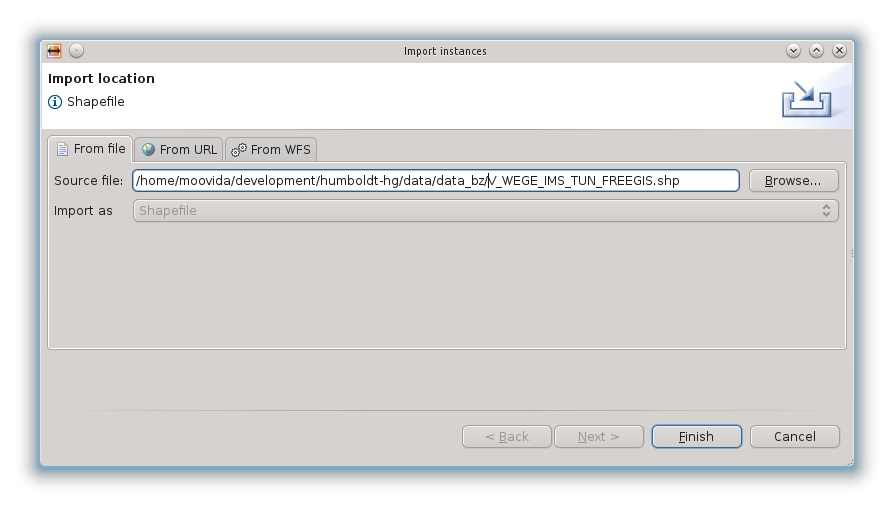
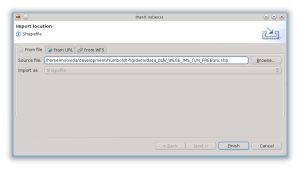
La procedura di import dei dati è simile a quella degli schemi, selezionando source data come tipo di import:
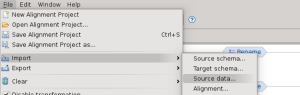
Il file da importare nel caso di questo esempio è lo stesso usato per definire lo schema:
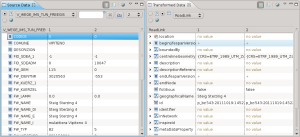
Una volta importato il dato, viene visualizzato nella parte bassa dell’applicativo un set di esempio di dati originali e trasformati. Questo è molto utile per avere un idea dell’effettiva bontà della mappatura:
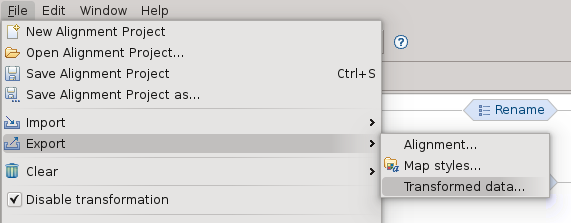
E’ infine possibile esportare il dato trasformato in formato GML, come richiesto da INSPIRE. Dal menu di export
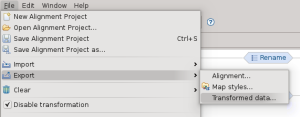
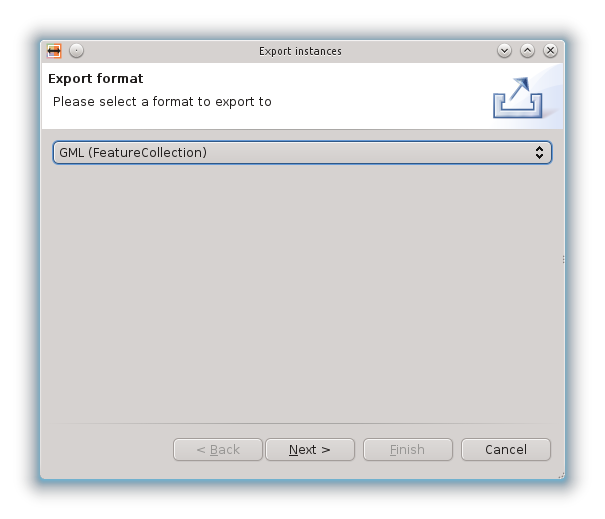
è possibile accedere alla procedura guidata che definisce il formato di output e poi esegue l’operazione di export:
Conclusioni
Non è facile scrivere un breve articolo riguardante strumenti così complessi. Me ne sono reso conto in modo sempre più decisivo durante la stesura di questo articolo.
Spero comunque di essere riuscito a suscitare interesse per Hale.
Spero che sia evidente l’importanza di avere uno strumento aperto e trasparente in processi di questo tipo. Personalmente starei attento a generare dipendenze da software chiusi e proprietari in processi complessi quali la migrazione dei dati. Queste procedure infatti si protraggono anche per parecchio tempo; non di rado passano per sperimentazioni, tentativi e possibili cambi di attori. Un software aperto a tutti – invece – permette maggiore autonomia e dà la possibilità, volendo, di seguire i processi a tutti i livelli desiderati. Non va dimenticato che in questi contesti è spesso necessario adattare lo strumento a casi specifici, quindi avere la possibilità di estenderlo e modificarlo può essere una carta vincente.
Spero infine che sia chiaro che la trasformazione di dati fra schemi non è una cosa impossibile (in caso la fatica sta nell’apprendere gli schemi INSPIRE). Ci sono strumenti validi a supporto e Hale - a mio avviso - è uno fra questi. Esorto le amministrazioni a cercare gli esperti dei dati sul proprio territorio e non affidarsi a softwarehouse che promettono il fatidico pulsante magico… non è realistico. I professionisti locali del settore conoscono bene lo stato dei dati e le reali problematiche ad essi legati e nessuno più di loro desidera che i dati migrati siano della giusta qualità.
Infine, ai temerari e amanti del genere lascio il link al video informativo reso disponibile dal DHP, nel quale vengono introdotti i tutorial inseriti dentro a Hale sotto forma di procedure guidate, che ne facilitano l’apprendimento.
Posted in osgeo, Strumenti | 5 Comments »
8 febbraio, 2013 | di Antonio Falciano
Una novità che sta circolando da poco più di un mese a questa parte e che, in pratica, interessa tutta la comunità italiana di fruitori dell’informazione geografica, consiste nella recentissima attivazione del servizio di trasformazione di coordinate ad opera del Geoportale Nazionale (ex Portale Cartografico Nazionale). Tale tipologia di servizio rientra tra gli adempimenti previsti dalle Implementing Rules della Direttiva europea INSPIRE (2007/2/EC), al fine di assicurare la condivisione e l’interoperabilità di dataset e servizi, adottando formati e specifiche comuni, tra tutti i nodi dell’infrastruttura di dati spaziali europea. In particolare, l’implementazione di tale servizio da parte del GN consiste in:
Per ulteriori approfondimenti circa le premesse e i dettagli tecnici, si consiglia la lettura di questo articolo sulla rivista Geomedia.
Benissimo! “Lasciamoci INSPIR(ar)E” dunque, parafrasando il titolo di un gran bel post di Pietro Blu Giandonato di qualche anno fa… E cosa avviene a livello regionale? In verità, esiste già qualche servizio analogo, tra cui:
Per curiosità, dopo aver letto un post nella lista GFOSS in cui erano segnalate delle inaspettate anomalie, ho deciso di impiegare qualche ritaglio di tempo libero per verificare la bontà del servizio WCTS della mia regione, la Basilicata, rispetto a quello appena reso disponibile dal GN. Nel seguito, non mi addentrerò nella descrizione qualitativa dei servizi (della serie …è più bello, è più brutto, è più veloce, mi chiede l’indirizzo email, ecc.), poiché esula completamente dai miei scopi.
In pratica, ho effettuato le seguenti operazioni:
- ho scaricato i confini amministrativi regionali dal sito dell’ISTAT, definiti in EPSG:23032, e li ho caricati in una vista di gvSIG 1.12, definita nello stesso sistema;
- ho poi selezionato solo la mia regione e applicato l’algoritmo di SEXTANTE “Adjust n points to polygon”, in modo tale da generare un set di 100 punti scelti in maniera casuale contenuti in Basilicata, utilizzando i parametri rappresentati in Figura 1 e ottenendo il risultato in Figura 2;
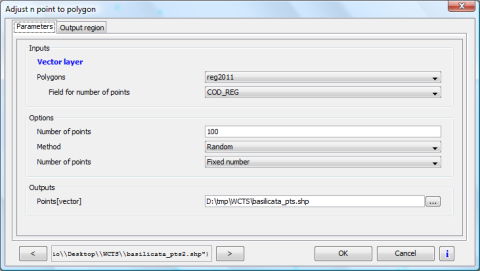
Figura 1 – Adjust n points to polygon
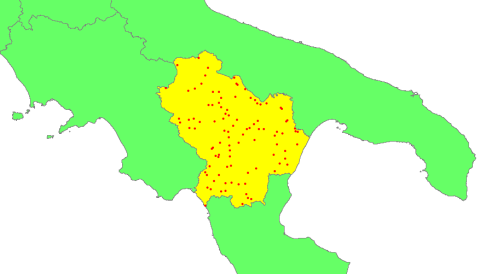
Figura 2 – Layer di punti casuali
- ho quindi trasformato il layer di punti precedentemente ottenuto, utilizzando sia l’applicazione web del Geoportale Nazionale che quella della Regione Basilicata, rispettivamente dal sistema EPSG:23032 (ereditato dal layer dei confini amministrativi ISTAT) verso EPSG:3004 e EPSG:32633, assumendo per buona ad occhi chiusi la conversione dovuta al passaggio di fuso/zona contenuta in maniera implicita in entrambe le trasformazioni, in quanto si tratta di un’operazione di coordinate che i software e le librerie GIS generalmente affrontano in maniera rigorosa e quindi fuori di discussione. Inoltre, ho trasformato – sempre utilizzando entrambi i servizi – il layer dei punti definito in EPSG:32633 ottenuto dal GN verso EPSG:3004. In definitiva, ho ottenuto tre coppie di layer, ognuna corrispondente ad ogni trasformazione possibile tra i tre sistemi citati e definita in un preciso sistema di destinazione. In Figura 3 sono rappresentate schematicamente le singole trasformazioni realizzate.
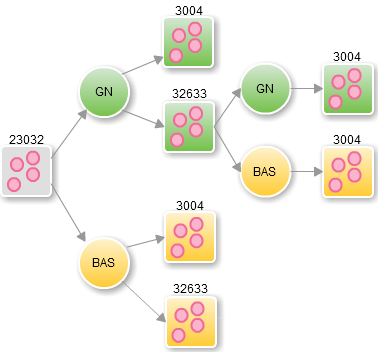
Figura 3 – Trasformazioni realizzate (Autore: Andrea Borruso)
- Il passo successivo è stato quello di definire e calcolare dei nuovi campi nelle tabelle associate ai layer ottenuti al punto precedente, contenenti le coordinate nei rispettivi sistemi di appartenenza (esistono diversi modi di farlo in gvSIG: con il “Calcolatore di campo”, con lo strumento “Aggiungi informazioni geometriche”, con “Add coordinates to points” di SEXTANTE …e tanti altri). Ho rinominato tali campi di coordinate in modo da poterli rapidamente associare al CRS di appartenenza, oltre che allo specifico servizio utilizzato. Ad esempio, X3004GN rappresenta la coordinata Est nel sistema EPSG:3004 trasformata dal Geoportale Nazionale, mentre X3004BAS è la corrispondente coordinata trasformata tramite il geoportale lucano.
- A questo punto, essendomi dimenticato di definire un campo identificativo da utilizzare come chiave esterna (in questo caso poco male, essendo i punti reciprocamente abbastanza distanti tra loro), ho eseguito il geoprocesso “Spatial join” per ogni coppia di layer definiti nello stesso CRS, selezionando l’opzione “Usa la geometria più prossima”, in alternativa al classico join tra tabelle. Il risultato di tale operazione è praticamente equivalente a quello del join, ad eccezione del fatto che gvSIG restituisce un campo DIST delle distanze tra le geometrie poste in relazione e, inoltre, il layer ottenuto è salvato su disco.
- Dulcis in fundo, ho calcolato le differenze tra coordinate omologhe al fine di verificare la bontà della trasformazione dei due servizi, assumendo quelle del GN come capisaldi in quanto dovrebbero essere quelle “ufficiali”.
I risultati di tutto l’ambaradan appena descritto, sperando di non avervi fin qui annoiato, sono riportati nella tabella seguente:
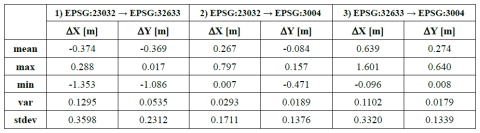
Tabella 1 – Statistiche degli scostamenti delle trasformazioni di coordinate del Geoportale della Basilicata (RSDI) rispetto a quelle del Geoportale Nazionale (GN)
A quanto pare, gli scostamenti tra le trasformazioni operate dai due servizi sono piuttosto importanti e, talvolta, addirittura superano il metro e mezzo! Se fossi un topografo, nel dubbio, mi guarderei bene dall’usare uno o l’altro servizio per trasformare i dati di un rilievo ad alta precisione. Ma anche un operatore GIS potrebbe imbattersi in qualche strana incongruenza topologica accostando dati provenienti da fonti (e quindi trasformazioni) diverse. Personalmente mi sarei aspettato differenze al più dell’ordine di un paio di decimetri per coordinata, ipotizzando dietro l’applicazione web del GN l’utilizzo di un unico grigliato comprendente tutta l’Italia a maglia più larga rispetto a quella dei singoli grigliati IGM, piuttosto che un numero elevato di griglie a passo fitto, decisamente più oneroso da gestire lato server.
Dalle statistiche di Tabella 1 chiaramente non si evince quale dei due servizi sia il meno accurato rispetto ai grigliati IGM. Eppure entrambi i servizi dichiarano di utilizzarli! Sarebbe utile, a mio avviso, ripetere lo stesso test con altri servizi WCTS regionali, magari utilizzando i grigliati come termine di confronto.
E’ lecito quindi chiedersi come mai la gestione informatica dei grigliati IGM all’interno di differenti applicazioni web porta a risultati diversi. E’ chiaro che occorrerebbe disporre di un riferimento ufficiale, unico ed inequivocabile.
A tal fine, per fugare ogni dubbio, sarebbe auspicabile il rilascio di un grigliato NTv2, formato ormai gestibile da molti desktop GIS, per ognuna delle possibili trasformazioni che interessano il nostro territorio nazionale. Non parlo necessariamente di quelli che utilizzano i topografi, ma anche solo una versione opportunamente semplificata che consenta di riunificare l’Italia intera, senza perdere eccessivamente in accuratezza. L’esempio lungimirante offerto da Francia, Spagna, Portogallo, Svizzera e Germania dovrà pur significare qualcosa nell’epoca di INSPIRE!
Aggiornamento del 09/02/2013
A seguito dell’aggiornamento ufficioso del servizio di trasformazione di coordinate del GN di cui si è avuta notizia ieri, i contenuti di questo post sono già obsoleti (forse, si tratta di un record per questo blog… ma siam contenti così! )
Ho quindi ricalcolato le medie degli scostamenti tra le trasformazioni dei due geoportali utilizzando lo stesso set di punti casuali. Il risultato è che le medie degli scostamenti sono stavolta sempre inferiori ai 3 cm. Restano tuttavia degli scostamenti max e min ancora consistenti (fino a 85 cm) per la coordinata Est. I valori estremi della coordinata Nord si aggirano invece attorno ai 20 cm, fatta eccezione per la trasformazione da EPSG:23032 a EPSG:32633, dove si superano i 30 cm.
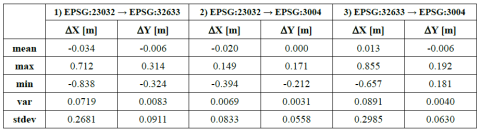
Tabella 2 – Statistiche degli scostamenti delle trasformazioni di coordinate del Geoportale della Basilicata (RSDI) rispetto a quelle del Geoportale Nazionale (GN) – agg. 09/02/2013
Resta, a mio modesto avviso, la necessità di dover rendere congruenti e quindi interoperabili i vari servizi di trasformazione di coordinate regionali con quello nazionale, evitando così l’eventuale disorientamento degli utenti. Inoltre, eviterei l’ulteriore proliferazione di servizi WCTS regionali, a questo punto ridondanti, e favorirei il rilascio e la diffusione dei grigliati NTv2, standard de facto a livello internazionale, almeno relativamente alla componente planimetrica.
Posted in Dati, osgeo | 16 Comments »
28 gennaio, 2013 | di Andrea Borruso
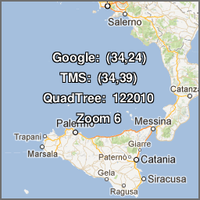 La cartografia digitale è ormai da tempo invasa da milioni di tasselli. I layer di Virtual Earth (che sono vecchio!), OpenStreetMap, Yahoo! Maps, Google Maps, ecc. sono da tempo distribuiti a pezzetti da 256×256 pixel e poi ricomposti nei nostri browser. Le modalità con cui la cosa viene realizzata sono “abbastanza” standard; se si prova però ad approfondire un po’, si scopre ad esempio una grande varietà nel definire l’indice numerico associato ad un dato tassello, di una certa zona del mondo, ad uno specifico livello di zoom. La mia amata/odiata Sicilia ad esempio, a livello di ingrandimento “6″, la posso richiamare nei modi diversi che vedete qui accanto, per tre dei più diffusi indici di tassellamento. Per approfondire il tema vi consiglio di partire da qui.
La cartografia digitale è ormai da tempo invasa da milioni di tasselli. I layer di Virtual Earth (che sono vecchio!), OpenStreetMap, Yahoo! Maps, Google Maps, ecc. sono da tempo distribuiti a pezzetti da 256×256 pixel e poi ricomposti nei nostri browser. Le modalità con cui la cosa viene realizzata sono “abbastanza” standard; se si prova però ad approfondire un po’, si scopre ad esempio una grande varietà nel definire l’indice numerico associato ad un dato tassello, di una certa zona del mondo, ad uno specifico livello di zoom. La mia amata/odiata Sicilia ad esempio, a livello di ingrandimento “6″, la posso richiamare nei modi diversi che vedete qui accanto, per tre dei più diffusi indici di tassellamento. Per approfondire il tema vi consiglio di partire da qui.
Nel tempo queste mattonelle cartografiche sono aumentate a dismisura e ce le troviamo anche in tasca. Penso ai nostri smartphone e al fatto che la quasi totalità delle basi cartografiche delle applicazioni che installiamo in questi sono distribuite a tasselli.
E nel prossimo futuro la diffusione sarà ancora più pervasiva, in quanto passeranno dall’essere consultati quasi esclusivamente tramite servizi/server web, all’essere letti direttamente da un file residente sul nostro terminale. Un esempio per tutti è quello del GeoPackage, un formato standard che l’OGC sta definendo, in cui le basi raster potranno essere archiviate proprio a tasselli. Un po’ come rasterlite di Sandro Furieri, che credo sia in qualche modo lo scheletro portante di questo nuovo formato OGC.
I tasselli sono talmente tanti che ormai spesso trovo negli hard-disk, pen-drive USB, DVD (come sono vecchio!), schede SD, ecc. quelle strane cartelle a loro volta suddivise in decine e decine (nel caso migliore) di sottocartelle, tipiche della struttura di archiviazione su file system di basi dati tassellate e piramidate.
Proprio per questo ho pensato di scrivere un articolo su come accedere ad un archivio cartografico di questo tipo, che in qualche modo è il complementare ad un altro scritto nel lontanissimo 2008 e in cui viene illustrato come tassellare un’immagine.
Come accedere ad un archivio cartografico a tasselli e ricomporlo in un unica immagine georeferenziata?
In sé la cosa sembra ovvia, in quanto si tratta di formati file leggibili da qualsiasi terminale con qualsiasi sistema operativo: parliamo infatti nella stragrande maggioranza dei casi di .jpg e .png. Sfoglio le cartelle, faccio doppio click su una delle immagini e le visualizzo in un attimo. E dove è finita l’informazione geografica?
Se le apro infatti con un visualizzatore di immagini è normale che le uniche coordinate riconosciute siano i pixel, ma se provate ad aprire lo stesso tassello con una applicazione GIS, il risultato non cambia. L’informazione geografica infatti non è presente nemmeno in qualche tag nascosto internamente ai file e quindi non può essere letta. Per assurdo tutti i tasselli sembrano sovrapposti nello stesso punto della terra, ad una sola risoluzione.
L’arcano si risolve proprio nella lettura della struttura della cartella in cui sono archiviati e quindi nella conoscenza dell’indice utilizzato per generare tutti i pezzetti di mondo alle varie scale di ingrandimento. Data infatti una certa modalità di tassellamento, ogni punto della terra è associato ad una certa tessera di questo enorme mosaico, per un certo livello di zoom.
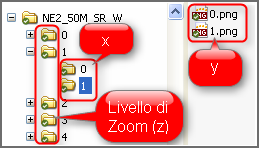 Ma sporchiamoci un po’ le mani. Nell’immagine accanto una cartella di output di un tassellamento, con le sue sottocartelle, che potete scaricare da qui. Se la si sfoglia un po’ e si provano ad aprire i singoli file che troviamo all’interno delle varie cartelle, è evidente che quello che varia per ogni tassello è l’ingrandimento e/o l’area della Terra rappresentata. Posizione e zoom, ovvero x, y e z.
Ma sporchiamoci un po’ le mani. Nell’immagine accanto una cartella di output di un tassellamento, con le sue sottocartelle, che potete scaricare da qui. Se la si sfoglia un po’ e si provano ad aprire i singoli file che troviamo all’interno delle varie cartelle, è evidente che quello che varia per ogni tassello è l’ingrandimento e/o l’area della Terra rappresentata. Posizione e zoom, ovvero x, y e z.
In questo esempio, ed è facile verificarlo in modo empirico, il primo livello di sottocartelle è legato all’ingrandimento: dalla cartella “0″ con la risoluzione più bassa a quella “4″ con quella più alta. All’interno di queste invece le eventuali sottocartelle rappresentano spostamenti lungo l’asse x. Nella figura di sopra quindi le cartelle “NE2_50M_SR_W\1″ e “NE2_50M_SR_W\1\1″ contengono, per il livello di zoom “1″, porzioni di Terra affiancate. La variazione lungo l’asse y è invece resa, per ogni cartella, dal nome del file: il tassello “1.png” sta a Nord di quello “0.png”.
Nella figura sottostante ho schematizzato la cosa, per rendere ancora più leggibile e chiara questa struttura.
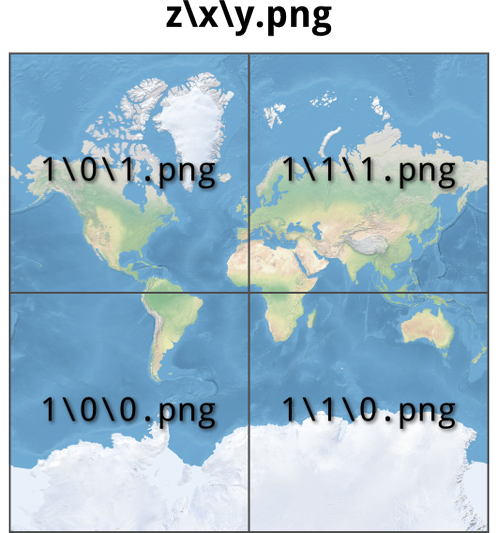
Conoscere tutto questo ovviamente non basta a posizionare queste immagini nello spazio, ma soltanto in modo relativo. Per fortuna però il tassellamento viene fatto secondo standard, magari diversi, ma definiti. Quindi se conosciamo (o riconosciamo) lo standard con cui sono state generate le nostre tessere, basterà essere in possesso di un client che sappia leggere questo standard e queste verranno posizionate correttamente nello spazio cartografico. Un po’ come quando accediamo ad un servizio WMS.
La cartella di esempio che sto usando per questo esercizio contiene al suo interno (per fortuna c’è quasi sempre qualcosa di simile) il seguente file .xml.
< ?xml version="1.0" encoding="utf-8"?>
<tilemap version="1.0.0" tilemapservice="http://tms.osgeo.org/1.0.0">
<title>NE2_50M_SR_W</title>
<abstract></abstract>
<srs>EPSG:900913</srs>
<boundingbox minx="-85.05112878000000" miny="-180.00000000000000" maxx="85.05112878000000" maxy="179.99871994141003"></boundingbox>
<origin x="-85.05112878000000" y="-180.00000000000000"></origin>
<tileformat width="256" height="256" mime-type="image/png" extension="png"></tileformat>
<tilesets profile="mercator">
<tileset href="0" units-per-pixel="156543.03390000000945" order="0"></tileset>
<tileset href="1" units-per-pixel="78271.51695000000473" order="1"></tileset>
<tileset href="2" units-per-pixel="39135.75847500000236" order="2"></tileset>
<tileset href="3" units-per-pixel="19567.87923750000118" order="3"></tileset>
<tileset href="4" units-per-pixel="9783.93961875000059" order="4"></tileset>
</tilesets>
</tilemap>
E’ un piccolo tesoro che ci dice quasi tutto della struttura a tasselli che stiamo analizzando:
- la specifica sul formato di tassellamento, ovvero il TMS 1.0 (Tile Map Service) di OSGeo;
- lo Spatial Reference System usato;
- il Bounding Box;
- l’origine del mosaico dei tasselli;
- formato e dimensioni dei tasselli;
- e la risoluzione per ogni livello di zoom.
Non ci resta che trovare un client compatibile con lo standard TMS e provare a leggere questa struttura dati. La scelta va ancora una volta verso il Victorinox delle librerie spaziali, ovvero GDAL/OGR. Sfruttando infatti i minidriver di GDAL, descritti in fondo nella pagina di accesso ai servizi WMS, è possibile accedere direttamente a dati esposti in TMS; sia come che su file system. Prima è però necessario definire un file di configurazione, come descritto nella documentazione di cui sopra e di cui si riporta a seguire un esempio, basato sui dati che sto usando per questo post.
<gdal_wms>
<service name="TMS">
<serverurl>
file://C:/tmp/NE2_50M_SR_W/${z}/${x}/${y}.png
</serverurl>
</service>
<imageformat>image/png</imageformat>
<datawindow>
<upperleftx>-20037508.34</upperleftx>
<upperlefty>20037508.34</upperlefty>
<lowerrightx>20037508.34</lowerrightx>
<lowerrighty>-20037508.34</lowerrighty>
<tilelevel>4</tilelevel>
<tilecountx>1</tilecountx>
<tilecounty>1</tilecounty>
</datawindow>
<projection>EPSG:900913</projection>
<blocksizex>256</blocksizex>
<blocksizey>256</blocksizey>
<bandscount>3</bandscount>
<maxconnections>10</maxconnections>
<cache></cache>
</gdal_wms>
Il file contiene, in modo differente, quasi le stesse informazioni descritte prime per il file .xml. Tra queste:
- il tipo di servizio - <service name>
- l’indirizzo per accedere ai dati - <serverurl>
- il formato immagine della sorgente dati - <imageformat>
- il Bounding Box - <upperleftx>, <upperlefty>, …
- il livello di Zoom con la risoluzione più alta, che ricavo proprio dal file.xml di sopra - <tilelevel>
- lo Spatial Reference System - <projection>
- la dimensione in pixel dei tasselli - <blocksizex>, <blocksizey>
Il valore del parametro ServerUrl – ovvero l’indirizzo della sorgente dati – è di solito quello di un servizio web con una forma di questo tipo: http://myserver.it/NE2_50M_SR_W/${z}/${x}/${y}.png.
Nel caso descritto i dati sono su un hard-disk di un PC e quindi, l’accesso non è in HTTP ma secondo lo schema URI di accesso a file: file://C:/tmp/NE2_50M_SR_W/${z}/${x}/${y}.png (in questo esempio la cartella dei dati è all’interno di “C:\tmp”).
Nell’URI è necessario indicare come è realizzata, in termini di struttura e nomi dei file, la mappatura di x, y e z. Nel caso in esame abbiamo visto che è resa come z/x/y.png, e cosi è stata riportata nel file di configurazione. Bisogna soltanto fare attenzione alla sintassi che prevede l’utilizzo di alcuni caratteri speciali.
Creato il file di configurazione e salvato con nome (ad esempio “input.txt”), non resta che provare a leggere i dati. Il primo passo, un po’ per fare debug è aprire la shell e digitare:
gdalinfo input.txt
Come risultato, se tutto è correttamente configurato, si otterrà:
Driver: WMS/OGC Web Map Service
Files: input.txt
Size is 4096, 4096
Coordinate System is:
PROJCS[\"Google Maps Global Mercator\",
GEOGCS[\"WGS 84\",
DATUM[\"WGS_1984\",
SPHEROID[\"WGS 84\",6378137,298.257223563,
AUTHORITY[\"EPSG\",\"7030\"]],
AUTHORITY[\"EPSG\",\"6326\"]],
PRIMEM[\"Greenwich\",0,
AUTHORITY[\"EPSG\",\"8901\"]],
UNIT[\"degree\",0.01745329251994328,
AUTHORITY[\"EPSG\",\"9122\"]],
AUTHORITY[\"EPSG\",\"4326\"]],
PROJECTION[\"Mercator_2SP\"],
PARAMETER[\"standard_parallel_1\",0],
PARAMETER[\"latitude_of_origin\",0],
PARAMETER[\"central_meridian\",0],
PARAMETER[\"false_easting\",0],
PARAMETER[\"false_northing\",0],
UNIT[\"Meter\",1],
EXTENSION[\"PROJ4\",\"+proj=merc +a=6378137 +b=6378137 +lat_ts=0.0 +lon_0=0.0 +x_0=0.0 +y_0=0 +k=1.0 +units=m +nadgrids=@null +wktext +no_defs\"],
AUTHORITY[\"EPSG\",\"900913\"]]
Origin = (-20037508.340000000000000,20037508.340000000000000)
Pixel Size = (9783.939619140624900,-9783.939619140624900)
Image Structure Metadata:
INTERLEAVE=PIXEL
Corner Coordinates:
Upper Left (-20037508.340,20037508.340) (180d 0' 0.00\"W, 85d 3' 4.06\"N)
Lower Left (-20037508.340,-20037508.340) (180d 0' 0.00\"W, 85d 3' 4.06\"S)
Upper Right (20037508.340,20037508.340) (180d 0' 0.00\"E, 85d 3' 4.06\"N)
Lower Right (20037508.340,-20037508.340) (180d 0' 0.00\"E, 85d 3' 4.06\"S)
Center ( 0.0000000, 0.0000000) ( 0d 0' 0.01\"E, 0d 0' 0.01\"N)
Band 1 Block=256x256 Type=Byte, ColorInterp=Red
Overviews: 2048x2048, 1024x1024, 512x512, 256x256
Band 2 Block=256x256 Type=Byte, ColorInterp=Green
Overviews: 2048x2048, 1024x1024, 512x512, 256x256
Band 3 Block=256x256 Type=Byte, ColorInterp=Blue
Overviews: 2048x2048, 1024x1024, 512x512, 256x256
Siamo riusciti a leggere correttamente le informazioni sui nostri dati e non abbiamo avuto nessun errore. A questo punto il comando per la ricomposizione in un’unica immagine georeferenziata è la cosa più ovvia, è gdal_translate:
gdal_translate input.txt output.tif
L’output sarà un unico file geotiff, Mission Accomplished!
Questo ovviamente è un caso semplice, costruito in modo che sia replicabile e didatticamente valido. Nella pratica quotidiana è tutto un po’ più complicato, ma leggendo i riferimenti indicati nell’articolo, documentandosi un po’, sarà possibile replicare la cosa con i propri dati.
La carta di base da cui ho generato i tasselli (che poi ho ricomposto) è la bella “Natural Earth II with Shaded Relief and Water“. E’ rilasciata sotto pubblico dominio e scaricabile da qui.
Con i minidriver di GDAL/OGR si possono fare tante altre cose, come accedere e quindi (volendo) scaricare, i tasselli di Bing Maps e Google Maps, facendo però la giusta attenzione ai termini legali imposti. Inoltre il file di testo di input creato sopra, può essere trascinato in drag & drop su Quantum GIS e visualizzato pochi secondi dopo. Questo sempre grazie all’esistenza degli standard e di GDAL/OGR.
Questo articolo diverrà magari presto “superato” proprio perché l’invasione dei tasselli sarà probabilmente peggiore di un attacco zombie, e saranno pertanto sviluppate modalità di accesso, procedure e interfacce ancora più semplici e trasparenti. Il fatto di poter accedere al basso livello descritto in questo articolo, offre comunque una potenza e una libertà di impieghi che difficilmente si potrà ottenere tramite strumenti di livello più alto.
In ultimo ringrazio Lorenzo Perone che mi ha dato gli stimoli per mettere in linea questi pensieri e questo processo.
Posted in Didattica, osgeo | No Comments »
11 dicembre, 2012 | di Andrea Antonello
All’inizio di novembre mi arrivo’ una comunicazione riguardante il rilascio di SpatiaLite per Android. Il mittente era Sandro Furieri, ben noto per essere il padre di SpatiaLite, nonché il presidente di GFOSS.
Era un periodo tutt’altro che ideale, stavo faticando a preparare la presentazione per il GFOSS day, che si sarebbe tenuto solo pochi giorni dopo.
Ma considerato che la mia presentazione avrebbe tentato di fare una sorta di cronologia del mercato mobile e il punto riguardo alla questione Android e GFOSS, non potevo ignorare una questione che ritengo cambierà le sorti dello spatial sul mobile. Quindi passai qualche notte a integrare SpatiaLite in Geopaparazzi.
Durante la presentazione che diedi alla conferenza:
mostrai solo una schermata nella quale Geopaparazzi dialogava con papà Furieri, chiedendogli delle trasformazioni di coordinate (si veda slide 50).
Ma da quel momento in poi non sono più riuscito a smettere di pensare al formato raster+vettoriale per lo scambio di dati fra sistemi operativi e dispositivi diversi.
Con SpatiaLite sarebbe stato finalmente possibile visualizzare nelle mappe di Geopaparazzi non solo punti e linee semplici, ma anche poligoni e grandi set di dati. Gli indici spaziali sarebbero stati d’aiuto, ne ero sicuro.
Quindi iniziammo ad implementare un nuovo piano in Geopaparazzi: il piano dei dati di tipo SpatiaLite.
E i primi risultati, usando i dati del progetto Natural Earth erano promettenti:

Natural Earth in Geopaparazzi
In itinere producemmo anche un breve tutorial per sviluppatori che volessero cimentarsi. Lo potete trovare qui.
Testammo la nuova versione su diversi dispositivi e in campo per un lavoro nelle paludi finlandesi, mentre validavamo i limiti dei bacini estratti durante le analisi idrolo-geomorfologiche. E visto che funziono’ cosi’ bene, decidemmo di rilasciare la versione, anche se non la si può ancora definire ottimizzata.
La seguente schermata mostra la sovrapposizione di una mappa di orienteering finlandese con i risultati delle analisi idrologiche: i limiti del bacino e i corsi d’acqua vecchi, nuovi e quelli estratti:

Mappe raster e vettoriali finlandesi
Avete notato la nuova icona sotto le icone di zoom? Quello e’ il pulsante per interrogare i dati. E’ possibile tracciare un rettangolo con le dita e l’applicazione mostra gli attributi degli oggetti compresi:

Interrogazione degli attributi su dati vettoriali
Questo ovviamente apre un nuovo mondo per Geopaparazzi ma in generale per lo sviluppo mobile geospaziale.
Un ringraziamento speciale va a Sandro per l’aiuto con l’ottimizzazione delle query spaziali e il supporto nello sviluppo praticamente in tempo reale.
Questa indubbiamente e’ la novità maggiore di Geopaparazzi 3.4.0, ma in realtà ve ne e’ una seconda abbastanza importante. In questa release e’ supportata anche la lettura di tag RFID via tecnologia NFC oppure bluetooth. La funzionalità e’ stata esposta all’utente all’interno delle schede personalizzate:

Scheda di rilevamento di tag RFID
E’ possibile inserire nelle schede un pulsante per la lettura del tag. Premendo il pulsante, si apre la schermata di scansione:

Schermata di scansione tag RFID via NFC oppure bluetooth
E’ possibile leggere i tag RFID sia attraverso la funzionalità NFC del dispositivo, ma anche attraverso antenne esterne collegate via bluetooth.
Una volta che l’id del tag e’ stato letto, il campo della scheda verrà compilato.
Una nota dolente dell’aggiunta di Spatialite deriva dal fatto che il pacchetto Geopaparazzi cresce da meno di 2 megabyte a più o meno 9 megabyte. Non abbiamo dubbi riguardo al fatto che tutti gli utenti saranno comunque contenti, vista la fantastica aggiunta.
Credo sia tutto per questa release. Speriamo possiate apprezzarla!
E’ possibile scaricare Geopaparazzi da:

la documentazione utente per questa versione e’ disponibile nel WIKI del sito principale.
Posted in osgeo, Strumenti | 1 Comment »