







Nel corso del 2012 ho avuto il piacere di collaborare al progetto FreeGIS. Il mio compito è stato quello di testare l’usabilità di un particolare software di mappatura di schemi di dati per mappare e successivamente convertire un set di dati della provincia di Bolzano verso lo schema di dati INSPIRE.
Considerato che ogni volta che scrivo la parola INSPIRE mi tremano le mani e ogni volta che ne parlo mi trema la voce, è stata un’esperienza interessante, anche al fine di smitizzare e abbattere alcuni muri, nonché confermare alcune assurdità che la complessità degli standard porta inevitabilmente con sé.
La certezza che ora ho è che la migrazione di dati verso gli schemi INSPIRE è una procedura molto complessa, ma non impossibile, e che richiede freddezza nella preparazione e personale capace e aggiornato da un punto di vista tecnico.
Io in generale non credo ai software dall’unico pulsante magico.
Credo però nel senso di una procedura guidata. Credo in un software che possa semplificare i passaggi importanti di tale procedura, supportando soprattutto la leggibilità degli schemi di dati e la consistenza delle mappature che si vanno ad operare.
Humboldt & Hale
Il software che ho avuto modo di testare (e poi anche estendere) si chiama Humboldt Alignment Editor (Hale per gli amici) e nasce da un progetto europeo che ha coinvolto 26 partner fra il 2006 e il 2011 (fra i quali gli italiani di CNR-IREA, GISIG, Telespazio e dell’Università di Roma). Il progetto Humboldt si è occupato principalmente dell’armonizzazione dei dati a livello europeo. Data la moltitudine e diversità dei dati presenti nelle varie organizzazioni europee, naturalmente non si trattava di re-inventare la magia nera, bensì di creare strumenti che potessero supportare il processo di implementazione.
Dal progetto Humboldt è nato il Data Harmonization Panel (DHP), una piattaforma di esperti nell’armonizzazione dei dati spaziali. Lo stesso DHP si pone tutt’oggi due importanti obiettivi:
- lo sviluppo ed il supporto degli strumenti sviluppati in Humboldt
- il supporto di un framework di formazione
Del progetto Humboldt oggi viene sviluppato in modo attivo praticamente solo la componente Hale. Il progetto è rilasciato con licenza Free ed Open Source alla community per facilitarne l’interazione ed il miglioramento.
E’ proprio la natura open del progetto che mi ha portato prima ad avvicinarmi a Hale attraverso FreeGIS e poi, in un secondo momento, quando ho avuto il piacere di essere chiamato a svilupparne alcune funzionalità nel team geospaziale del Fraunhofer IGD (attuale centro di coordinamento del progetto).
E’ stata questa collaborazione che mi ha ispirato a scrivere un articolo riguardante Hale in modo da renderlo un pochino più noto al di fuori della cerchia accademica e dei progetti europei.
Ma bando alla storia e passiamo alla parte pratica.
Utilizzare Hale
Per mostrare il funzionamento di base di Hale mi rifarò in parte al progetto FreeGIS usando i dati della Provincia di Bolzano e descritti nel eGeo, il geoportale della provincia. Mi riferirò in particolare al set di dati di quello che è definito in INSPIRE RoadLink dello schema dei TransportNetwork.
Per chi volesse cimentarsi, è possibile scaricare Hale dall’area di download del sito del progetto per i sistemi operativi più diffusi.
Una volta lanciato, Hale si presenta in questo modo:
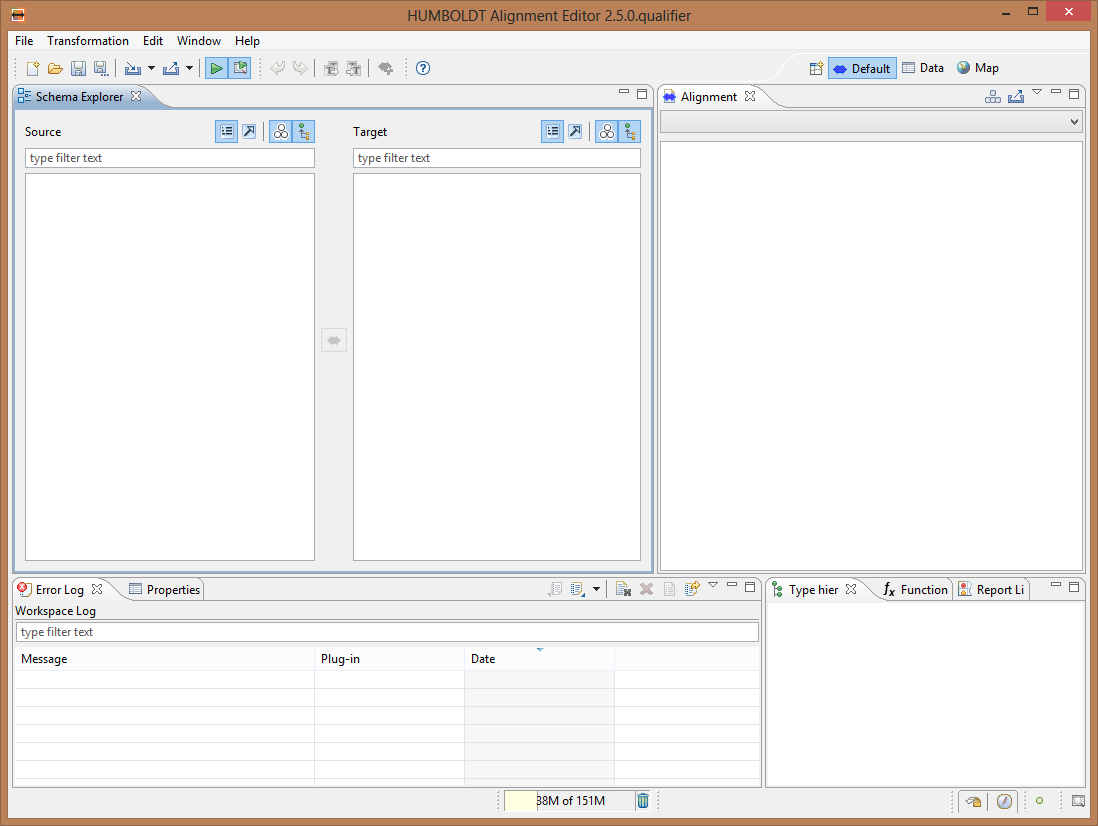
Le parti più importanti sono indubbiamente le viste dello Schema explorer e dell’Alignment.
Hale è stato concepito per mappatura di strutture di dati molto complesse, fra schemi di dati xml come lo possono essere ad esempio gli schemi CityGML. Il nostro esempio non renderà onore a questo potenziale, in questa sede si vuole piuttosto introdurre lo strumento in generale.
Definire lo schema di arrivo
La prima cosa da definire, è lo schema verso il quale si desidera mappare lo schema dei dati originali. Nel nostro caso si parla di dati del TransportNetwork, quindi è necessario caricare lo schema xml del RoadTransportNetwork di INSPIRE. Tale schema è scaricabile qui.
Una volta scaricato sul proprio disco rigido, è possibile importarne la definizione dal menu di import attraverso l’operazione target schema:
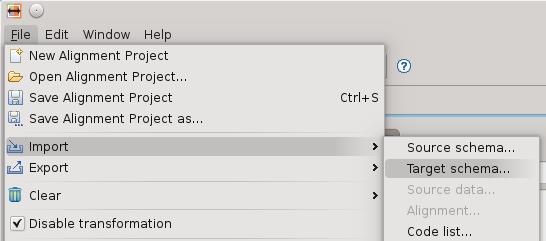
definendo poi nella procedura guidata il file da importare:
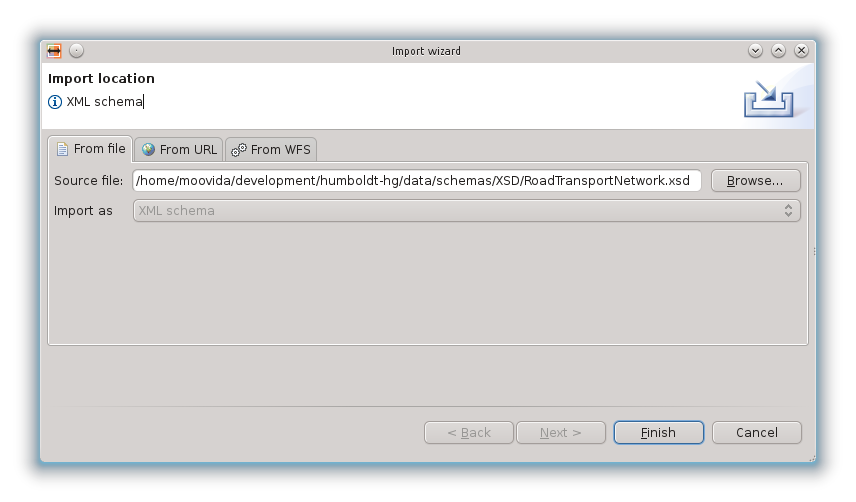
per poi trovarsi lo schema visualizzato nella sua struttura ad albero in Hale:
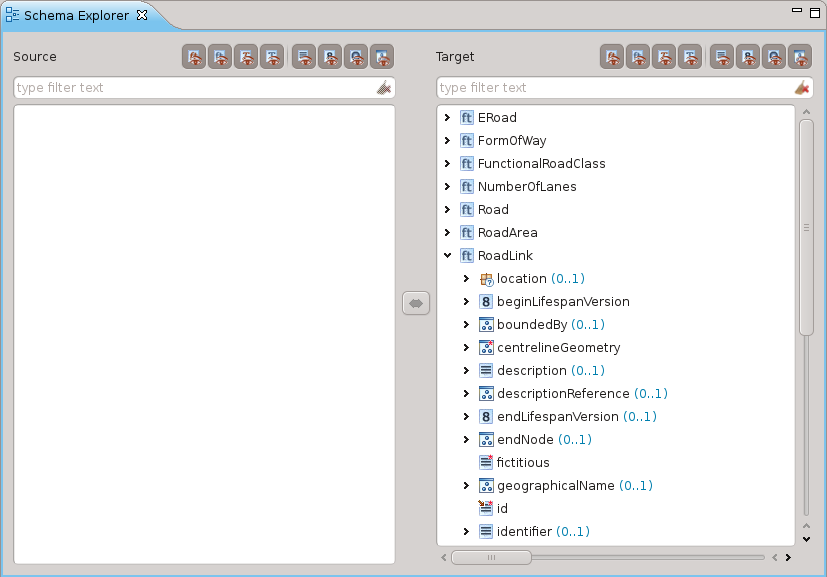
Da poco sono stati aggiunti alcuni schemi preconfigurati legati a INSPIRE, che si possono trovare nella tab denominata presets. Nel nostro caso lo schema di interesse è presente:
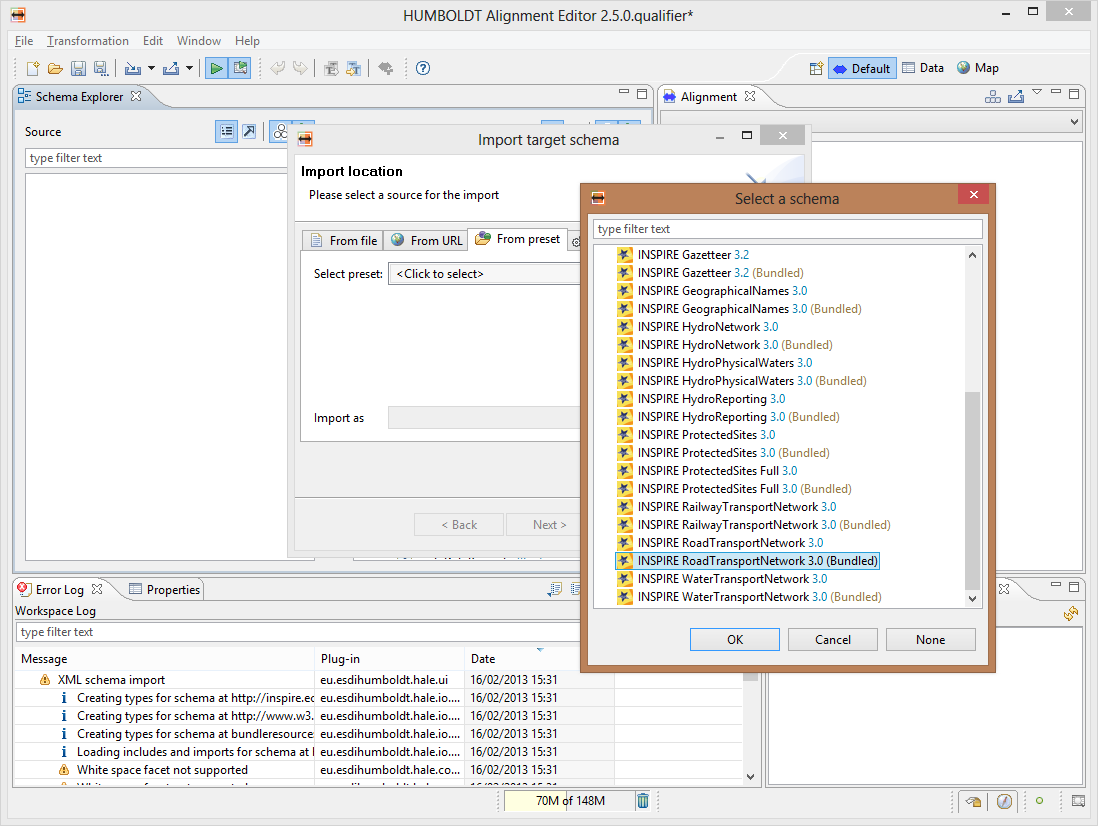
Definire lo schema di partenza
La definizione dello schema di partenza può essere una procedura semplice o molto complessa, dipendentemente dal formato in cui si sono mantenuti i propri dati (e questa è indubbiamente una scienza a parte). Hale permette l’import dello schema da file, ma anche da servizi WFS. Per set di dati molto semplici è possibile generare uno schema estraendolo da shapefile.
Come per il target schema, partendo nuovamente dal menu di import, procediamo ad importare il source schema:

per trovarci con la seguente situazione:

Nell’immagine la selezione è stata poi posizionata sui due tipi da mappare.
Come mappare gli schemi
Mappatura del tipo
La prima operazione da fare, è quella della mappatura dei tipi principali, in questo caso V_WEGE_IMS_TUN_FREEGIS verso il RoadLink INSPIRE.
Il dato di partenza pero’ contiene tutto il transport network (strade, ferrovie, etc), quindi bisogna procedere a creare una regola per estrarre solo le strade.
Con un GIS questa operazione è abbastanza triviale. In uDig l’operazione può essere fatta con il linguaggio CQL (Constraint Query Language).
Ad esempio ponendo delle condizioni sul campo giusto possiamo isolare le ferrovie:
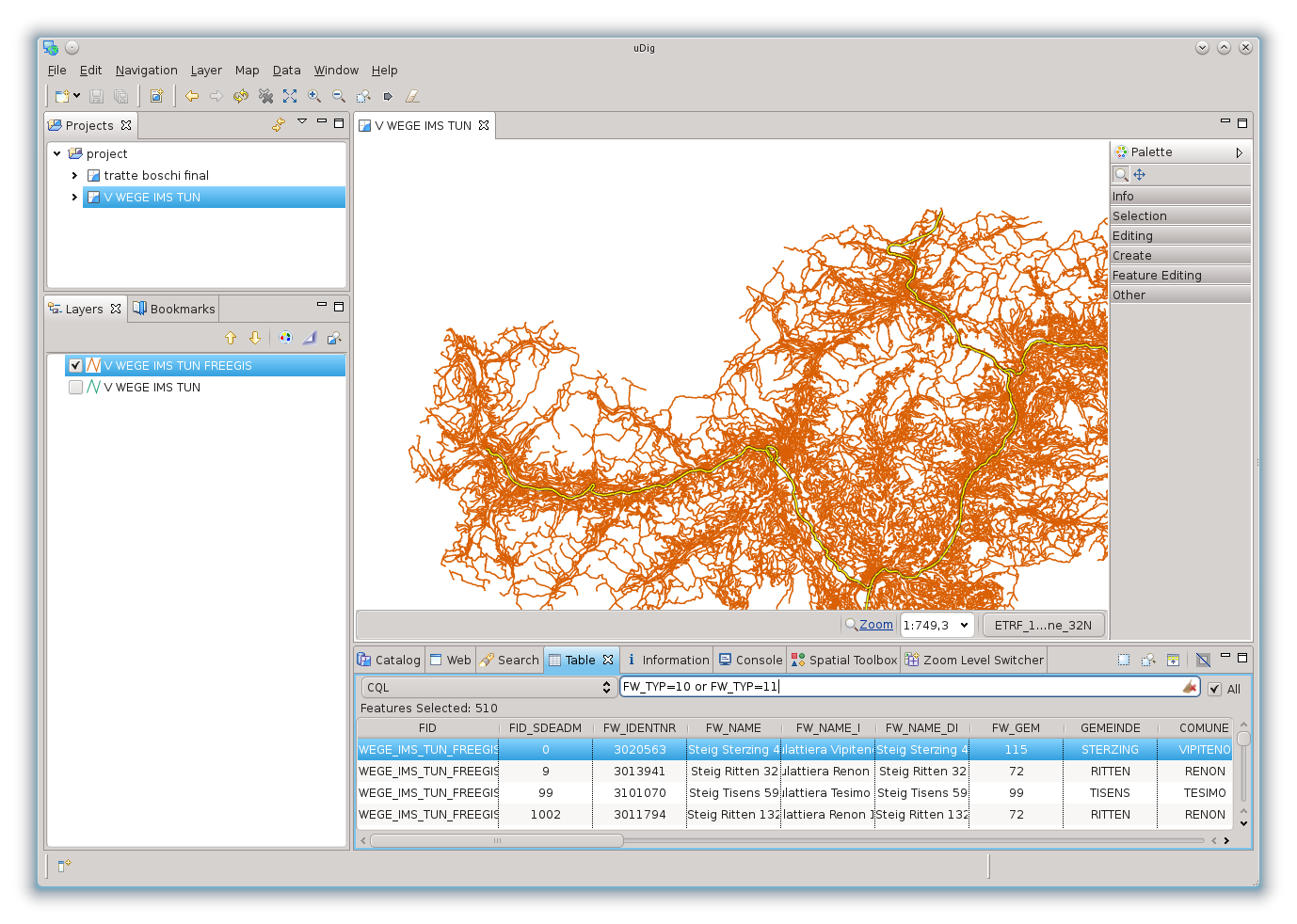
oppure, cosa necessaria al nostro esempio, le strade:
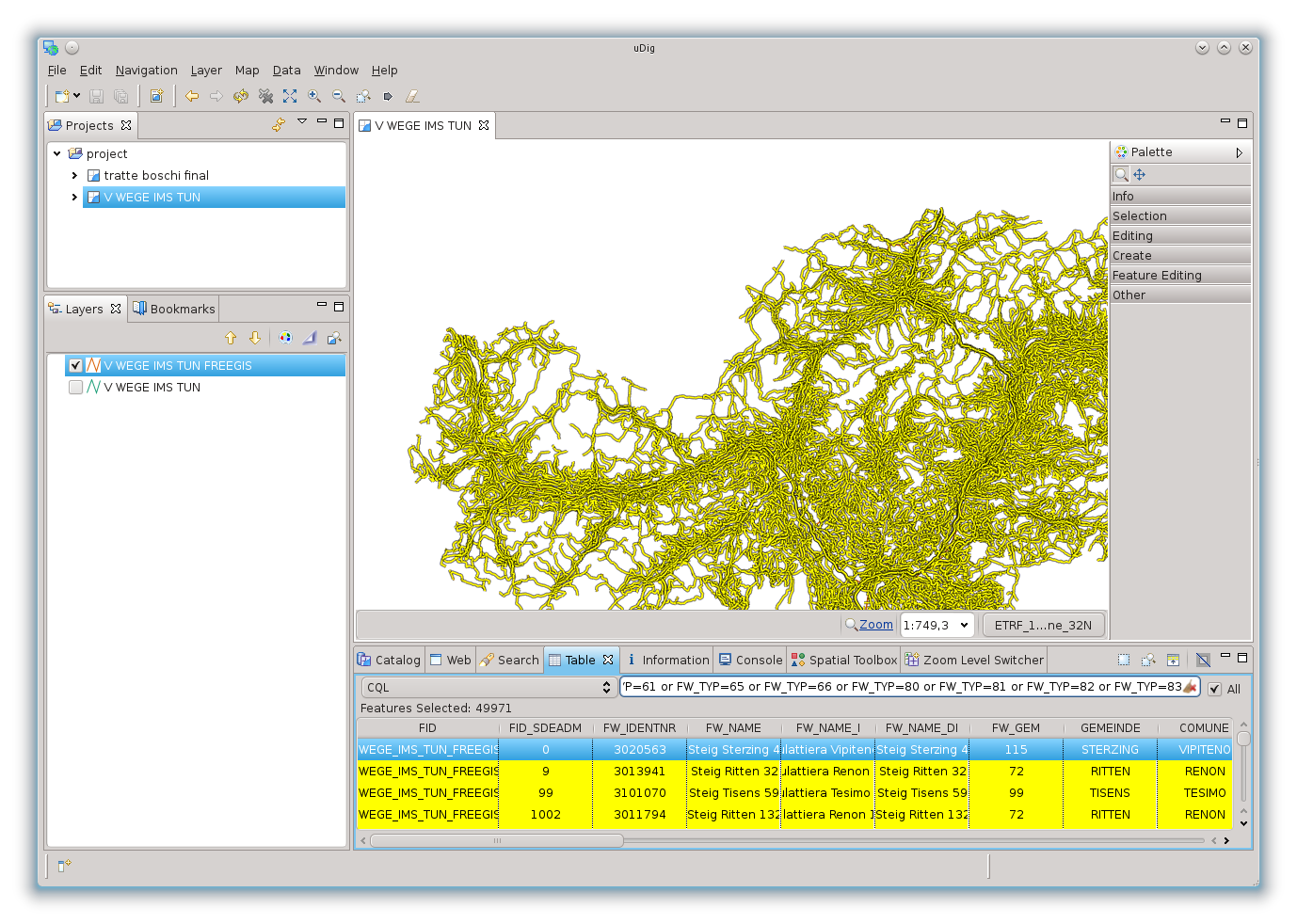
Il motivo per il quale vi cito uDig è duplice. Perché è il GIS con il quale lavoro e che supporto in modo attivo, ma anche perché Hale supporta lo stesso identico linguaggio CQL.
E’ quindi possibile creare un condition context:

usando come condizione esattamente la stringa testata in uDig:
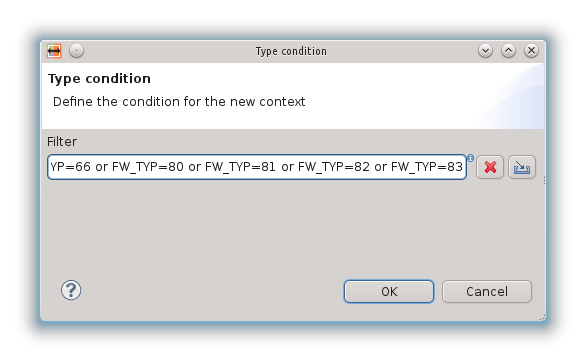
A questo punto Hale crea un nuovo tipo in base alla condizione imposta e sarà quello che verrà mappato attraverso un’operazione di Retype:
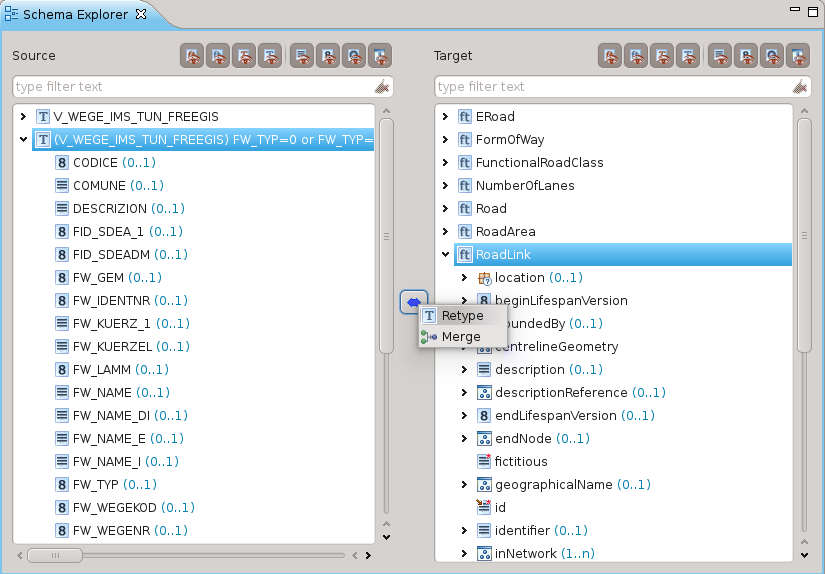
Una volta conclusa la procedura guidata, la mappatura sarà visualizzata nello schema explorer e nella vista dell’Alignment:
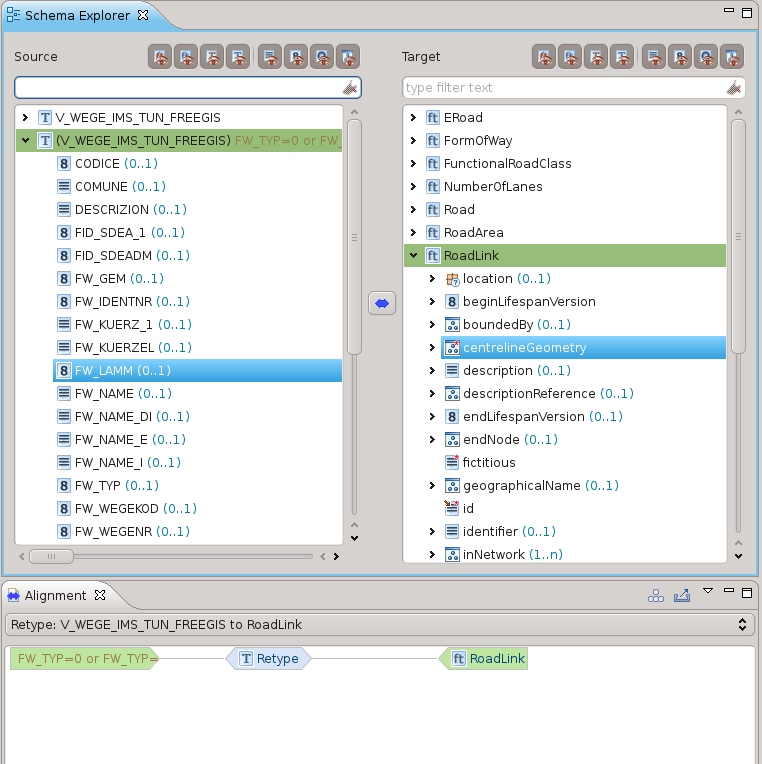
Mappatura degli attributi
Non voglio tediarvi con la descrizione dei vari attributi, quindi riassumerò solo alcune operazioni che si possono applicare per la mappatura degli attributi
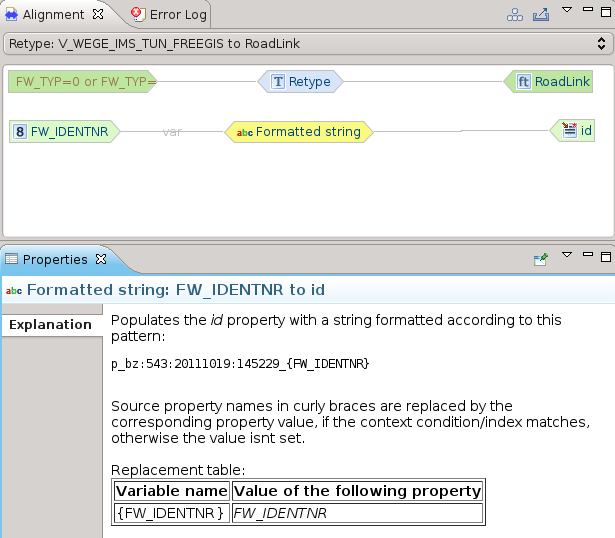
Formattazione di stringhe
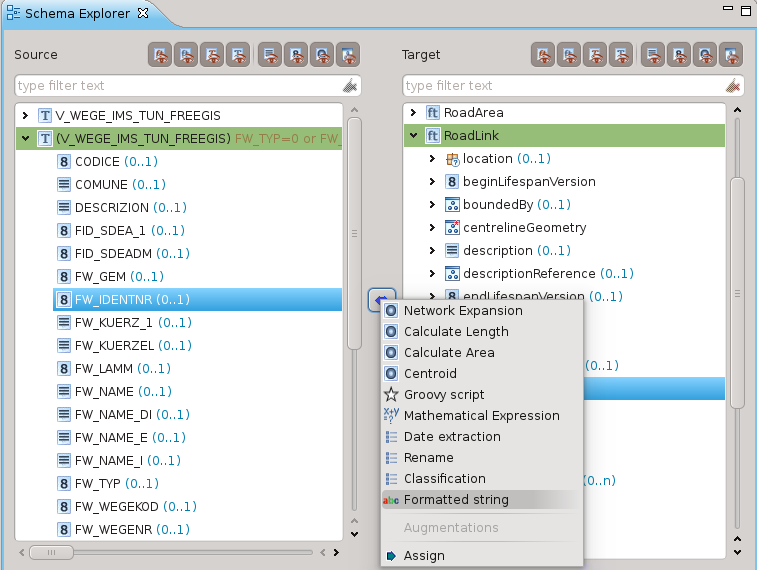
Permette di concatenare le stringhe dei diversi campi dello schema di partenza e delle costanti aggiunte manualmente per creare una stringa nello schema di arrivo:
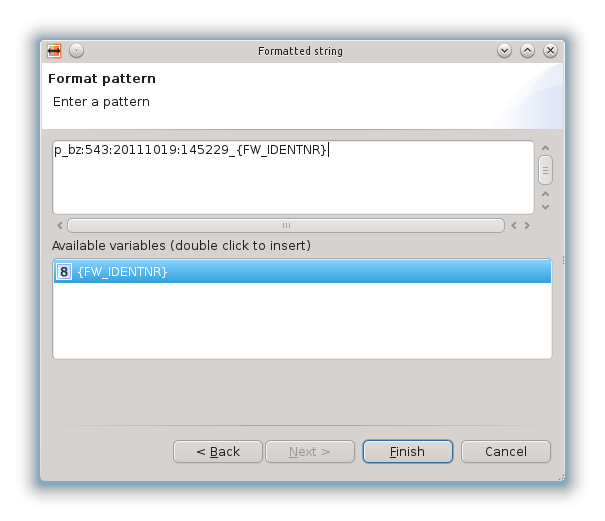
Appena applicata la mappatura, viene visualizzata nella Alignment View e la vista delle proprietà ci fornisce una descrizione dell’operazione applicata:
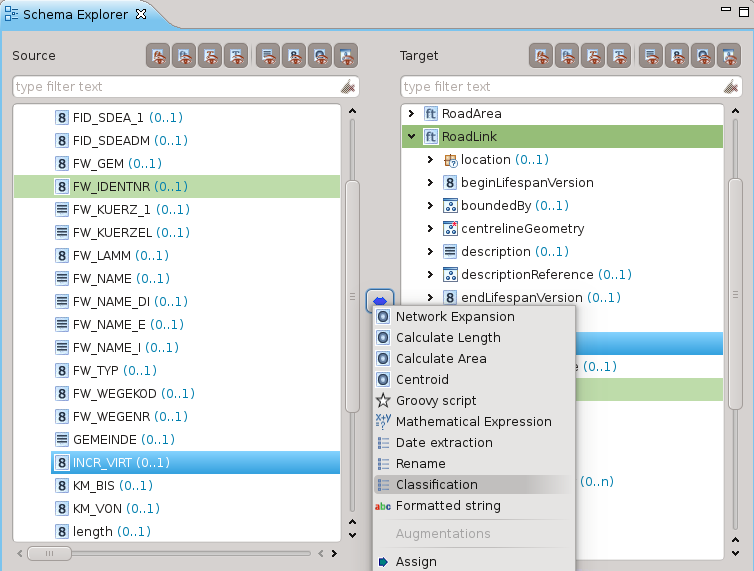
Classificazione
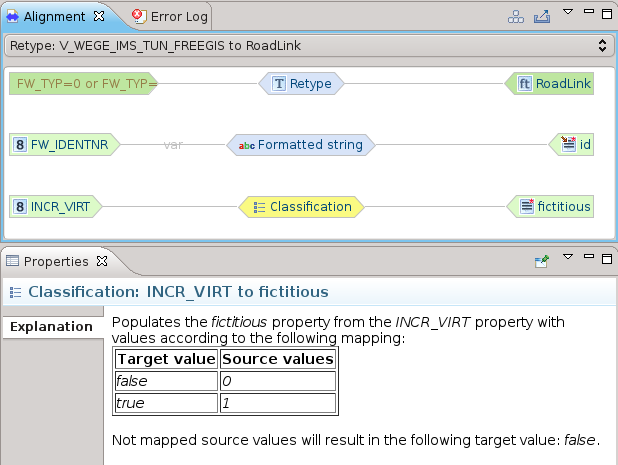
La classificazione è forse una delle operazioni più importanti, permette di mappare classi di valori.
Un esempio molto semplice è la mappature fra dei valori interi 0/1 al loro booleano nello schema di arrivo:
Mappatura della geometria
E’ possibile eseguire la mappatura di geometrie:
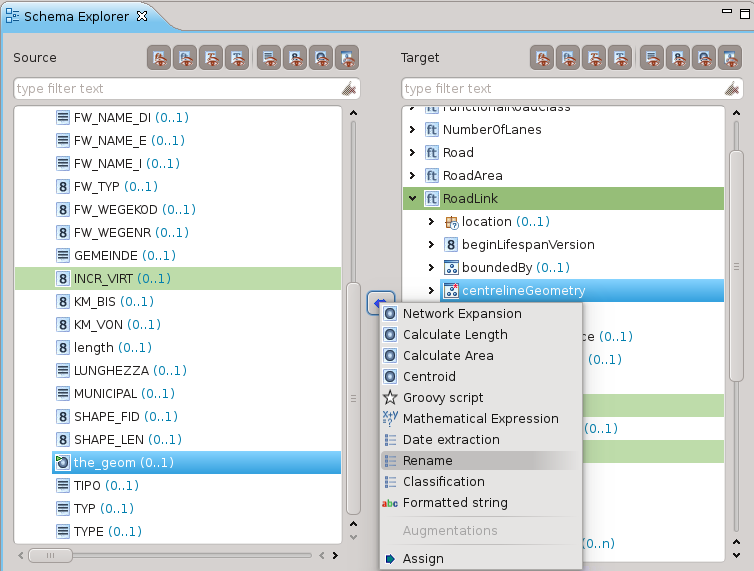
Il tipo nel nostro caso è lo stesso, quindi una operazione di rename è sufficiente:
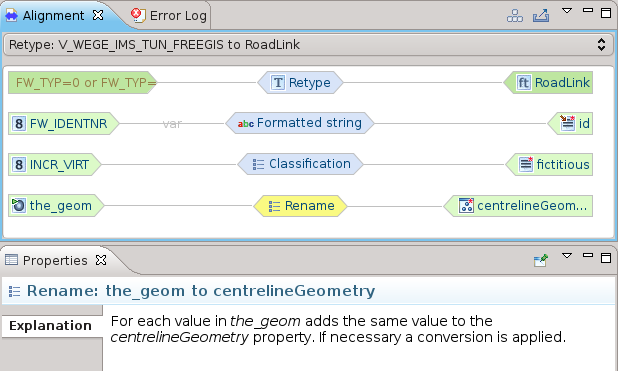
Non mi spingo oltre con la descrizione del processo di mappatura. Accenno solo al fatto che è possibile utilizzare anche degli script, cioè dei frammenti semplificati di programmi, che rendono possibili trasformazioni personalizzate molto complesse.
Controllo mappatura e trasformazione dati
Una volta conclusa la mappatura, la vista delle trasformazioni è quello che fa per noi. Ci permette di dare una controllata finale al grafico della trasformazione
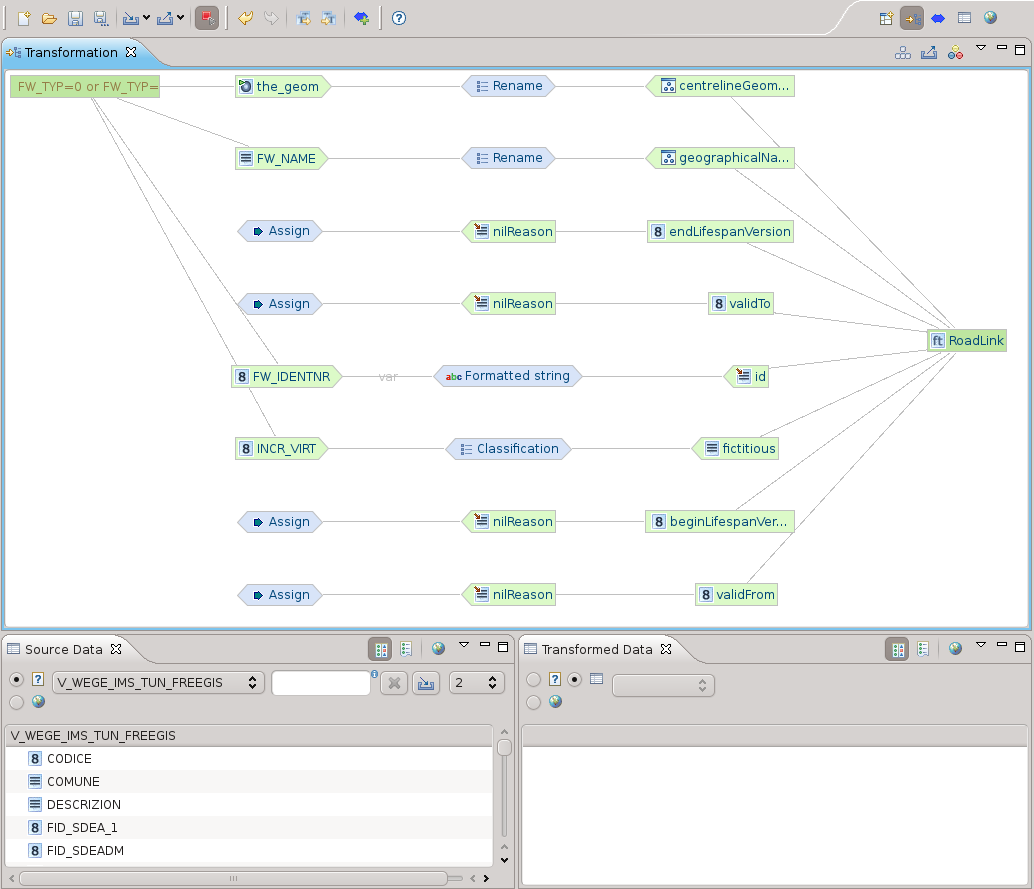
e la possibilità di caricare un set di dati per eseguire una trasformazione secondo la mappatura precedentemente prodotta.
La procedura di import dei dati è simile a quella degli schemi, selezionando source data come tipo di import:
Il file da importare nel caso di questo esempio è lo stesso usato per definire lo schema:
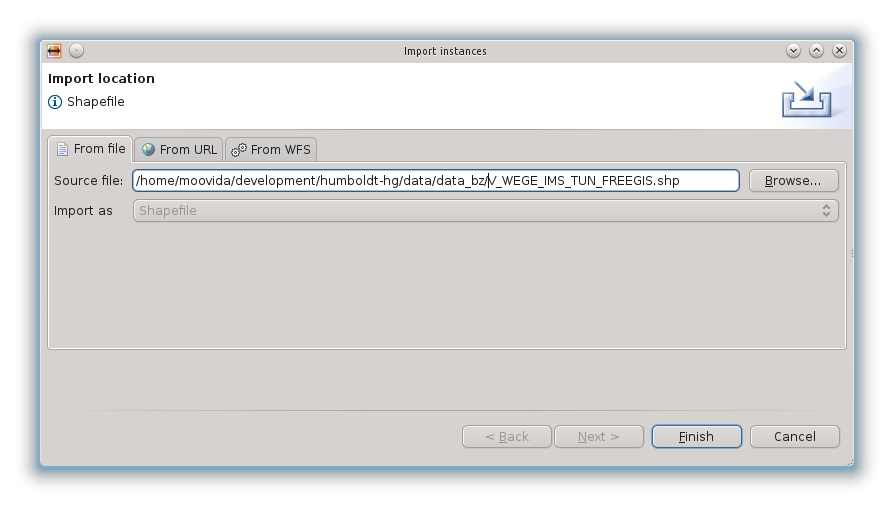
Una volta importato il dato, viene visualizzato nella parte bassa dell’applicativo un set di esempio di dati originali e trasformati. Questo è molto utile per avere un idea dell’effettiva bontà della mappatura:
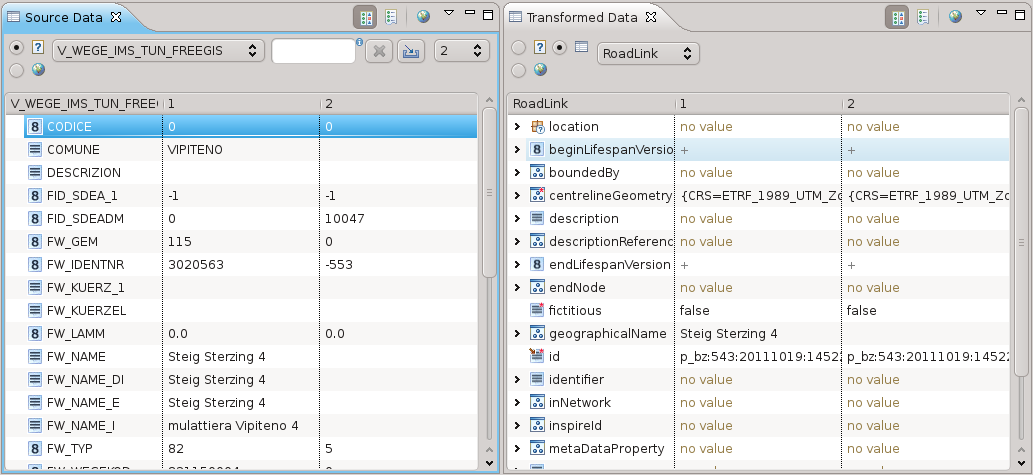
E’ infine possibile esportare il dato trasformato in formato GML, come richiesto da INSPIRE. Dal menu di export
è possibile accedere alla procedura guidata che definisce il formato di output e poi esegue l’operazione di export:
Conclusioni
Non è facile scrivere un breve articolo riguardante strumenti così complessi. Me ne sono reso conto in modo sempre più decisivo durante la stesura di questo articolo.
Spero comunque di essere riuscito a suscitare interesse per Hale.
Spero che sia evidente l’importanza di avere uno strumento aperto e trasparente in processi di questo tipo. Personalmente starei attento a generare dipendenze da software chiusi e proprietari in processi complessi quali la migrazione dei dati. Queste procedure infatti si protraggono anche per parecchio tempo; non di rado passano per sperimentazioni, tentativi e possibili cambi di attori. Un software aperto a tutti – invece – permette maggiore autonomia e dà la possibilità, volendo, di seguire i processi a tutti i livelli desiderati. Non va dimenticato che in questi contesti è spesso necessario adattare lo strumento a casi specifici, quindi avere la possibilità di estenderlo e modificarlo può essere una carta vincente.
Spero infine che sia chiaro che la trasformazione di dati fra schemi non è una cosa impossibile (in caso la fatica sta nell’apprendere gli schemi INSPIRE). Ci sono strumenti validi a supporto e Hale - a mio avviso - è uno fra questi. Esorto le amministrazioni a cercare gli esperti dei dati sul proprio territorio e non affidarsi a softwarehouse che promettono il fatidico pulsante magico… non è realistico. I professionisti locali del settore conoscono bene lo stato dei dati e le reali problematiche ad essi legati e nessuno più di loro desidera che i dati migrati siano della giusta qualità.
Infine, ai temerari e amanti del genere lascio il link al video informativo reso disponibile dal DHP, nel quale vengono introdotti i tutorial inseriti dentro a Hale sotto forma di procedure guidate, che ne facilitano l’apprendimento.
I contenuti potrebbero non essere più adeguati ai tempi!

By p1d1d1 on feb 18, 2013
Beh allora approfitto della tua esperienza. E’ da un po’ di tempo che cerco di utilizzare HALE, ma mi si blocca sull’import del “target schema”.
Ho gli schemi INSPIRE scaricati in locale, carico Address.xsd e l’operazione termina con un errore sull’import degli altri schemi, tipo CadastralParcels.xsd not found…..
Help please. Grazie,
Pasquale
By Andrea on feb 18, 2013
Ciao Pasquale, la cosa “divertente” del caricamento degli schemi, e’ che i collegamenti fra i vari schemi devono essere precisi.
Dove viene chiamato CadastralParcels e dove si trova sul disco rispetto al file che lo chiama?
Ciao,
Andrea
By sanguinela on dic 4, 2013
Ciao Andrea, bella e utile presentazione. Mi permetto di darti del tu visto il profilo informale del caso, spero non sia un problema.
Approfitto della tua esperienza anch’io per porti una domanda sperando tu sia in grado di rispondere:
con Hale posso mappare un campo geometry(sorce schema) verso un ulteriore campo geometry(target schema) estrapolando però da esso i boundary delle geometrie processate? Magari con uno script Groovy?
è possibile? e in che modo?
Grazie mille.
O.
By Andrea Antonello on dic 6, 2013
Ciao O.
dovrebbe esserci proprio una funzione che estrae il bounding box. Dai un’occhiata alla documentazione dentro a Hale, che e’ molto ben fatta. Cerca Functions, troverai tutto quello che e’ possibile.
Per domande techniche poi c’e’ il forum dedicato al supporto “volontario”:
http://www.esdi-community.eu/projects/hale/boards